MIT 6.824: Lecture 17 - Causal Consistency, COPS
· 6 min readIn studying distributed systems, I've come across systems like Spanner, which incurs additional latency for strong consistency, and DynamoDB, which sacrifices strong consistency for low latency in responding to requests. This latency vs consistency tradeoff is one that many systems have to make, and COPS—this lecture's focus—is no exception.
What the COPS (Cluster of Order-Preserving Servers) system offers, though, is a geo-replicated database with a consistency model that's closer to strong consistency while offering performance similar to low latency databases. This consistency model is called causal+ consistency.
COPS provides low latency querying by directing clients' requests to their local data centres and ensuring that these requests (both reads and writes) can proceed without waiting for or talking to other data centres. This is in contrast to a system like Spanner, where at least one other data centre must acknowledge writes.
The rest of this post will describe the causal+ consistency model and how COPS works.
Causal+ Consistency #
Causal+ consistency combines causal consistency with convergent conflict handling. I'll describe those next.
Causal Consistency #
Two operations are causally related if we can say that one happened before the other. Any system that implements causal consistency guarantees it will preserve this order across all replicas. If an operation a happens before an operation b, no replica should see the effect of operation b before it has seen the effect of operation a. Here, we say operation b is causally dependent on operation a or a is a dependency of b.
For example, let's assume we're building an e-commerce application and considering a merchant Ade and a customer Seyi. Here, Ade is trying to share a new item in her inventory with Seyi, which involves the following sequence:
- First, Ade uploads the item onto the platform and then adds it to her online inventory.
- Seyi then checks Ade's inventory, expecting to see the new item added.
Under causal consistency, if the inventory has a reference to the new item, then Seyi must be able to see the item. Weaker consistency models may not guarantee this. In eventually consistent systems, the operations to upload the item and then add it to the inventory may get reordered during replication and lead to a situation where Seyi sees a reference to the item but not the item itself.
Potential Causality #
More formally, the paper mentions three rules that the authors used to define potential causality between operations, denoted ->:
- Execution Thread. If a and b are two operations in a single thread of execution, then a
->b if operation a happens before operation b.- Gets From. If a is a put operation and b is a get operation that returns the value written by a, then a
->b.- Transitivity. For operations a, b, and c, if a
->b and b->c, then a->c
The execution in Figure 1 illustrates these rules.
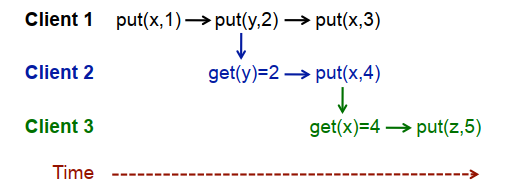
Figure 1 - Graph showing the causal relationship between operations at a replica. An edge from a to b shows that a happened before b, or b depends on a.
The execution thread rule gives get(y)=2 -> put(x,4); the gets from rule gives put(y,2) -> get(y)=2; and the transitivity rule gives put(y,2) -> put(x,4).
If you're wondering how a system can determine causal relationships between operations at different replicas, you'll find out in a later section.
Convergent Conflict Handling #
Causal consistency does not order concurrent operations. We say that two operations are concurrent if we cannot tell that one happened before the other. A system can replicate two unrelated put operations in any order, but when there are concurrent put operations to the same key, we say they conflict.
Quoting the lecture paper:
Conflicts are undesirable for two reasons. First, because they are unordered by causal consistency, conflicts allow replicas to diverge forever. For instance, if a is
put(x,1)and b isput(x,2), then causal consistency allows one replica to forever return 1 for x and another replica to forever return 2 for x.Second, conflicts may represent an exceptional condition that requires special handling. For example, in a shopping cart application, if two people logged in to the same account concurrently add items to their cart, the desired result is to end up with both items in the cart.
Convergent conflict handling requires that a causal+ system handles all conflicting puts in the same way across all replicas through a handler function h. The last-writer-wins rule is commonly used in handler functions to ensure that replicas eventually converge.
Causal+ vs Eventual and External Consistency #
With the above properties, causal+ consistency differs from eventual consistency in that an eventually consistent system may not preserve the causal order of operations, leaving clients to deal with the inconsistencies that may arise.
Also, unlike in external consistency, which always returns the most up-to-date version, a causal+ system may return stale versions of a value. What causal+ guarantees though is that those stale values are consistent with a causal order of operations.
Let's now look at COPS, a system which implements this causal+ consistency model.
COPS #
Overview #
COPS (Cluster of Order-Preserving Servers) is a geo-replicated key-value storage system that guarantees causal+ consistency. It comprises two software components: a client library and the key-value store.
Each data centre involved has a local COPS cluster which maintains its copy of the entire dataset. A COPS client is an application that uses the client library to interact with the key-value store. Clients interact only with their local COPS cluster running in the same data centre.
COPS shards the stored data across the nodes in a cluster, with each key belonging to a primary node in each cluster. This primary node receives the writes for a key. After a write completes, the primary node in the local cluster replicates it to the primary nodes in the other clusters.
Each key also has versions, which represent different values for that key. COPS guarantees that once a replica has returned a version of a key, the replica will only return that version or a causally later version in subsequent requests.
COPS clients maintain a context #
Each client maintains a context to represent the order of its operations. Think of this context as a list that holds items. After each operation, a client adds an item to its context. The order of these items in the list captures the dependencies between versions.
This works in line with the earlier section on potential causality. Using this context, a client can compute the dependencies for a version.
Lamport timestamps provide a global order #
It is easy for a COPS client to determine the order of operations on a key in a local cluster based on its context, but when there are concurrent operations to the same key in different clusters—a conflict—we need another way to determine that order.
COPS uses Lamport timestamps to derive a global order over all writes for each key. With Lamport timestamps, all the replicas will agree on which operation happened before the other.
Writing values in COPS #
Writes to the local cluster #
When a client calls put for a key, the library computes the dependencies for that key based on its context and sends that information to the local primary storage node. This storage node will not commit the key's value until the COPS cluster has written all the computed dependencies.
After committing the value, the primary storage node assigns it a unique version number using a Lamport timestamp and immediately returns that number to the client.
By not waiting for the replication to complete, COPS eliminates most of the latency incurred by systems with stronger consistency guarantees.
Write replication between clusters. #
The primary storage node asynchronously replicates a write to the other clusters after committing a write locally. The node includes information about the write's dependencies when replicating it.
When a node in another cluster receives this write, the node checks if the local nodes in its clusters have satisfied all the dependencies. The receiving node does this by issuing a dependency check request to the local nodes responsible for those dependencies.
If a local node has not written the dependency value, it blocks the request until it writes the value. Otherwise, it will respond immediately.
In summary, COPS guarantees causal+ consistency by computing the dependencies of a write, and not committing the write in a cluster until the cluster has committed all the dependencies.
Reading values in COPS #
COPS also satisfies reads in the local cluster. A COPS client can specify whether they want to read the latest version of a key or a specific older one. When the client library receives the response for a read, it adds the operation to its context to capture potential causality (See "Execution Thread" and "Gets From" above).
Limitations #
While causal+ consistency is a popular research idea, it has some limitations. Two major ones are:
- It cannot capture external causal dependencies. The classic example for this is a phone call: if I do action A, call my friend on another continent to tell her about A, and then she does action B, a system will not capture the causal link between A and B.
- Managing conflicts can be difficult, especially when last-writer-wins isn't sufficient.
Conclusion #
The authors don't compare COPS with other systems in terms of performance or ease of programming in its evaluation section, which I found surprising given that the central thesis is that COPS has a better tradeoff between ease of programming and performance.
I've also left out some details about COPS here around fault tolerance and how it handles transactions, but I hope you've gotten a good idea of causal+ consistency and how one might implement it. I recommend reading the paper linked below if you want to know more.
Further Reading #
- Don’t Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS - Original 2011 paper on COPS.
- Causal Consistency, COPS - MIT 6.824 lecture notes.
- A Short Primer on Causal Consistency - Wyatt Lloyd, Michael J. Freedman, Michael Kaminsky, and David G. Andersen.