MIT 6.824: Lecture 13 - Spanner
· 10 min readUnlike many other databases that either choose not to support distributed transactions at all or opt for weaker consistency models, Spanner is an example of a distributed database that supports externally consistent distributed transactions.
This post will cover how Google Spanner implements a fault-tolerant two-phase commit protocol and how its novel TrueTime API enables it to guarantee external consistency.
Table of Contents
- Overview
- Spanner's read-write transactions use locks
- Read-only transactions
- TrueTime
- Conclusion
- Further Reading
Overview #
Spanner partitions data into Paxos groups #
Spanner partitions data across many servers in data centres spread all over the world. It manages the replication of a partition using Paxos, and each partition belongs to a Paxos group. Paxos is like Raft in that each Paxos group has a leader, and the leader replicates a log of operations to its followers. Each replica in a Paxos group is typically in a different data centre.
This setup is great for a few reasons:
- Partitioning the data means we can increase the total throughput via parallelism.
- Data centres fail independently and so Spanner can continue to serve clients even after a data centre failure.
- With global replication, clients can read data faster by going to the replicas closest to them.
- Paxos only requires a majority of the replicas to respond and can tolerate slow or distant replicas.
Spanner guarantees external consistency #
I've written about external consistency in another post, but to summarize, external consistency is the "gold standard" for isolation levels in distributed databases.
Serializability is often referred to as the gold standard, but while serializability guarantees that the result of concurrent transactions will be the same as if they had executed in some serial order, external consistency (sometimes referred to as strict serializability) imposes what that order must be. It guarantees that the order chosen will be one that is consistent with the real time execution of those transactions.
Using the example from the linked post where we execute two transactions, T1 and T2, in a database. Let's assume that the database replicates the data across two machines A and B, which are both allowed to process transactions.
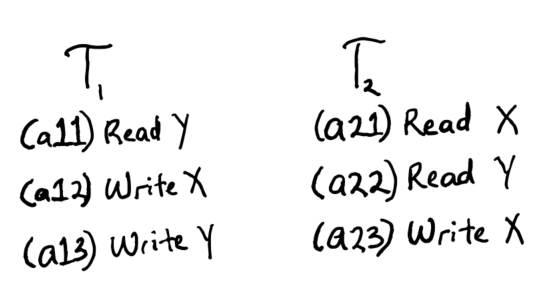
Sample Transactions T1 and T2
A client issues transaction T1 to machine A which performs the operations a11, a12 and a13. After T1 completes, another client issues transaction T2 to machine B. Under serializability, it would be valid for transaction T2 to not see the latest value of Y written by T1, even though T2 started after T1 completed.
This is because the order where T2 executes before T1 is one of the two possible serial schedules for these transactions:
Sa: {a11, a12, a13, a21, a22, a23}
Sb: {a21, a22, a23, a11, a12, a13}
This scenario could happen if the database uses asynchronous replication, and the writes from T1 have not yet replicated to machine B.
External consistency guarantees that if transaction T1 commits before transaction T2 starts, then T2 will see the effects of T1 regardless of what replica it executes on.
There is no difference between serializability and external consistency in a single-node database. By committing a transaction on a single-node database, it becomes visible to every transaction that starts after it.
External consistency is challenging to provide #
One reason distributed databases are partitioned and replicated in data centres spread across multiple locations is to allow clients to make requests to the local replicas closest to them, which yields better performance. However, this arrangement makes it harder to provide strong consistency guarantees, as it means that reads of local replicas must always return fresh data. The challenge here is that a local replica may not have been involved in a Paxos majority, which means it won't reflect the latest Paxos writes.
The protocols needed to provide external consistency have performed poorly in terms of availability, latency, and throughput when implemented, which is why many database designers with an arrangement similar to Spanner's have either chosen not to support distributed transactions or to provide weaker guarantees than external consistency.
Spanner tackles this problem by making clients specify whether a transaction is read-only or read-write before executing and making optimizations tailored to each case. The rest of this post will explain how it does that.
Spanner's read-write transactions use locks #
Read-write transactions that involve only one Paxos group or partition use two-phase locking for external consistency. The client issues writes to the leader of the Paxos group, which then manages the locks.
For transactions that involve multiple Paxos groups, Spanner uses the two-phase commit protocol with long-held locks to guarantee that read-write transactions provide external consistency. In the previous discussion of the two-phase commit protocol, we saw that one of its downsides is how the coordinator can be a bottleneck. I highlighted in the summary that if there is a coordinator failure, there is the risk of the transaction participants being stuck in a waiting state. Spanner solves this problem by combining two-phase commit with the Paxos algorithm. It replicates the transaction coordinator and participants into Paxos groups so it can automatically elect a new coordinator on failure, and the protocol is more fault-tolerant.
The client buffers the write operations that occur in a transaction until it is ready to commit. At commit time, it chooses a leader of one of the Paxos groups to act as the transaction coordinator and sends a prepare message with the buffered writes and the identity of the coordinator to the leaders of the other participant groups. Each participant leader then acquires writes locks and performs the specified operations before responding to the coordinator with the status of its mini-transaction.
The client also issues reads within read-write transactions to the leader replica of the relevant group, which acquires read locks and reads the most recent data. One of the other limitations of two-phase commit highlighted in the previous lecture is its proneness to deadlocks. Spanner uses the wound-wait locking rule to avoid deadlocks when reading data.
By holding locks on the data and ensuring that only the Paxos leader of the partition it belongs to can read or write the data, read-write transactions in Spanner are externally consistent.
Now, if Spanner only supported read-write transactions, then it would be fine to leave it with this protocol. But Spanner was built for a workload dominated by read-only transactions. The next section will cover how Spanner's protocol for read-only transactions achieves 10x latency improvements over read-write transactions.
Read-only transactions #
Spanner makes two optimizations to achieve greater performance in read-only transactions:
-
It does not hold locks or use the two-phase commit protocol to serve requests.
-
Clients can issue reads involving multiple Paxos groups to the follower replicas of the Paxos groups, not just the leaders. This means that a client can read data from their local replica.
But these optimizations make it more difficult to provide external consistency. For example, a read request may be sent to a stale replica which may violate external consistency if it returns its latest committed value.
Something else to note is that reads in a read-only transaction only see the values that had been committed before the transaction started, even if a R/W transaction updates those values and commits while the transaction is running.
Why not read the latest committed values? #
It might seem like transactions must read the latest committed values to guarantee external consistency, but the next example from the lecture shows why this behaviour could violate the property.
Suppose we have two bank transfers, T1 and T2, and a transaction T3 that reads both.
T1: Wx Wy C
T2: Wx Wy C
T3: Rx Ry
If T3 reads the value of x from T1 and y from T2, the results won't match any serial order.
Not T1, T2, T3 or T1, T3, T2.
We want T3 to see both of T2's writes or none.
We want T3's reads to *all* occur at the *same* point relative to T1/T2.
Read-only transactions in Spanner use snapshot isolation to prevent the violation in the example.
Snapshot Isolation #
With snapshot isolation, a database keeps multiple versions of an object—each version labelled with a timestamp representing what transaction produced it. Spanner assigns a timestamp to each transaction using these rules:
-
For a read-only transaction, Spanner chooses the time at the start of the transaction as the transaction timestamp (TS). Spanner has an API layer on the machines in the cluster which uses the system clock to get the current time.
-
The leader of the coordinator group in charge of a read-write transaction chooses its time when commit begins as the transaction timestamp.
Snapshot isolation enforces that a read-only transaction will only see the versions of a record that have a timestamp less than its assigned transaction timestamp i.e. a snapshot of what the record was before the transaction started.
This prevents the problem in the previous example as it guarantees that T3 will see either both of T2's writes or none. Here's another version of the example with snapshot isolation implemented:
x@10=9 x@20=8
y@10=11 y@20=12
T1 @ 10: Wx Wy C
T2 @ 20: Wx Wy C
T3 @ 15: Rx Ry
"@ 10" indicates the time-stamp.
- Now,T3's reads will both be served from the @10 versions.
T3 won't see T2's write even though T3's read of y occurs after T2.
- The results are now serializable: T1 T3 T2.
The serial order is the same as the time-stamp order.
In this example, it is okay for T3 to read an older value of y even though there is a newer value because T2 and T3 transactions are concurrent, and external consistency allows either order for concurrent transactions.
But there is another problem that may arise in the example. T3 can read x from a local replica that hasn't seen T1's write because the replica wasn't in the Paxos majority. To prevent this violation, each replica maintains a safe time property, which is the maximum timestamp at which it is up to date. Paxos leaders send writes to followers in timestamp order and the safe time represents the most recent timestamp a replica has seen.
Before serving a read at time 20, a replica must have seen Paxos writes for time > 20, or it will have to wait until it is up to date.
What if the clocks on the replicas are not synchronized? #
Imagine a scenario where the clocks on each replica are wildly different from each other. Remember that these clocks are used to assign transaction timestamps. How do you think that will affect the correctness of transactions? Does your answer depend on whether we are considering read-only or read-write transactions? I'll answer these questions in this section, but I suggest taking a minute to think about them before moving on.
Unsynchronized clocks will not affect the correctness of read-write transactions because they acquire locks for their operations and don't use snapshot isolation. As stated earlier, the locks guarantee external consistency and ensure that the transactions operate on recent data.
But for a read-only transaction spanning multiple Paxos groups, the effect of unsynchronized clocks can play out in two ways:
-
If Spanner assigns a timestamp that is too large, that transaction timestamp will be higher than the safe time of the replicas in the other Paxos groups involved, and the read will block until they are up to date. Here, the result will be correct, but the execution will be slow.
-
If the transaction timestamp is too small, the transaction will miss writes that have committed on other replicas before it started. Remember that the snapshot isolation rule mandates that a transaction can only read values below its timestamp. Let's look at the example below where T2 is assigned a timestamp less than T1, even though T1 committed first.
r/w T0 @ 0: Wx1 C r/w T1 @ 10: Wx2 C r/o T2 @ 5: Rx? (C represents a commit)This would cause T2 to read the version of x at time 0—which was 1—even though T2 started after T1 committed (in real time). External consistency requires that T2 sees x=2.
The next section will discuss how Google uses its TrueTime service to synchronize computer clocks to high accuracy.
TrueTime #
Clocks are unreliable in distributed systems. A computer's time is defined by clocks at a collection of government labs and distributed to the computer via various protocols — NTP, GPS or WWV. This distribution to different computers is subject to variable network delays, and so there's always some uncertainty in what the actual time is.
TrueTime is a globally distributed clock that Google provides to applications on its servers. It uses GPS and atomic clocks as its underlying time reference to ensure better clock synchronization between the participating servers than other protocols offer. For context, Google mentions an upper bound of 7ms for the clock offsets between nodes in a cluster, while using NTP for clock synchronization gives somewhere between 100ms and 250ms.
TrueTime models the uncertainty in clocks #
The beauty of TrueTime is that it also models the uncertainty in clocks by representing time as an interval. When you ask for the current time, it gives you an interval that represents what the earliest and latest possible values for the current time are. TrueTime's protocol guarantees that this interval is accurate and that the correct time is somewhere in the interval.
Table 1 below shows the TrueTime API.

From the paper, the TT.now() method returns a TTinterval that is guaranteed to contain the absolute time during which TT.now() was invoked. Note also that the endpoints of a TTinterval are of type TTstamp.
Spanner uses TrueTime to guarantee external consistency through the start and commit wait rules, which we'll look at next.
Start rule #
This states that a transaction's timestamp, TS, must be no less than the value of TT.now().latest. Recall from an earlier section that:
- For a RO transaction, Spanner assigns TS at the start of the transaction.
- For a RW transaction, Spanner assigns TS when commit begins.
The start rule enforces that the value chosen for TS must be greater than or equal to TT.now().latest.
Commit Wait #
This applies to only read-write transactions and ensures that a transaction will not commit until the chosen transaction timestamp has passed, i.e. when TT.after(TS) is true. Before a node can report that a transaction has committed, it must wait for about 7ms.
This rule guarantees that any transaction that starts after a read-write transaction has committed will be given a later transaction timestamp.
Using the rules #
Let's look at the example below which updates the earlier examples with intervals and the commit wait rule. The scenario here is T1 commits, then T2 starts, and so T2 must see T1's writes i.e. we need TS1 to be less than TS2.
|1-----------10| |11--------------20|
r/w T1 @ 10: Wx2 P C
|10--------12|
r/o T2 @ 12: Rx?
(where P stands for the 'prepare' phase in the two-phase protocol)
In this example, we assume the database assigns TS1 as 10, which guarantees that C will occur after time 10 due to commit wait. We also assume that Rx in T2 starts after T1 commits, and thus after time 10. T2 chooses TT.now().latest() as its transaction time (start rule), which is after the current time, which is after 10. Therefore TS2 > TS1.
Going back to the definition of external consistency which is that a transaction that starts after an earlier one commits should see the effects of the earlier one, this protocol provides that safety because:
- Commit wait guarantees that the timestamp for a read-write transaction is in the past.
- The timestamp used for snapshot isolation in a read-only transaction (TT.now().latest) is guaranteed to be greater than or equal to the correct time, and thus greater than or equal to the timestamp of any previously committed transaction (because of commit wait).
Conclusion #
Spanner has inspired the creation of other systems like CockroachDB and YugaByteDB in its use of tightly synchronized clocks to provide external consistency, but its design hasn't come without criticism. "NewSQL database systems are failing to guarantee consistency," Daniel Abadi wrote in a 2018 post, "and I blame Spanner."
Further Reading #
- Spanner: Google's Globally-Distributed Database - Original Spanner paper.
- Lecture 13: Spanner - MIT 6.824 Lecture Notes.
- Life of Cloud Spanner Reads & Writes - Official Spanner documentation.
- Serializability vs “Strict” Serializability: The Dirty Secret of Database Isolation Levels by Daniel Abadi and Matt Freels.
- Linearizability vs Serializability by Peter Bailis.
- Serializable vs Snapshot Isolation by Craig Freedman.
- NewSQL database systems are failing to guarantee consistency, and I blame Spanner by Daniel Abadi
- Spanner: Google's Globally-Distributed Database - Murat Demirbas' summary of the Spanner paper.
- Living without Atomic Clocks by Spencer Kimball and Irfan Sharif on the CockroachDB blog. CockroachDB is a database based on Spanner's design.
- I've written more about snapshot isolation in another post.