MIT 6.824: Lecture 12 - Distributed Transactions
· 5 min readDistributed databases typically divide their tables into partitions spread across different servers which get accessed by many clients. In these databases, client transactions often span the different servers as the transactions may need to read from various partitions. A distributed transaction is a database transaction which spans multiple servers.
A transaction with the correct behaviour must exhibit the following, also known as the ACID properties:
-
Atomicity: Either all writes in the transaction succeed or none, even in the presence of failures.
-
Consistency: The transaction must obey application-specific invariants.
-
Isolation: There must be no interference from concurrently executing transactions. The ideal isolation level is serializable isolation. This guarantees that the result of the execution of concurrent transactions will be the same as if the database executed the transactions one after the order. I've written about serializability more extensively here and here, and I'll recommend reading them if you're interested in learning more about it.
-
Durability: Committed writes must be permanent.
These properties are more difficult to guarantee when a transaction involves multiple servers. For example, the transaction may succeed on some servers and fail on others. There needs to be a protocol to ensure that the database maintains atomicity even in that scenario. Also, if several clients are executing transactions concurrently, we must take extra care to control access to the shared data for those transactions.
This post will focus on how distributed databases provide atomicity through an atomic commit protocol known as Two-phase commit, and how concurrency control methods like Two-phase locking help to guarantee serializability.
Note: I've written about some of these topics in other posts on this site, so I'll be posting links to them if you want more detail.
Table of Contents
Concurrency Control #
Concurrency control ensures that concurrent transactions execute correctly, i.e., that they are serializable. There are two classes of concurrency control for transactions:
- Pessimistic: Here, a transaction must place locks on the shared data objects that it wants to access before doing any actual reading or writing. When another transaction wants to access any of those records, it must wait for the original transaction to release those locks.
- Optimistic: In this class, transactions read or modify records without placing any locks on them. However, when it's time to commit the transaction, the system checks if the reads/writes were serializable, i.e. if the transaction's results are consistent with a serial order of execution. If not, the database aborts the transaction and retries it.
Pessimistic concurrency control is faster if there are frequent conflicts between concurrent transactions, while optimistic concurrency control is faster when the conflicts are rare. We'll cover optimistic concurrency control in a later post.
Pessimistic Concurrency Control #
There are two pessimistic concurrency control mechanisms highlighted in the lecture material for ensuring serializable transactions:
- Simple locking
- Two-phase locking
Simple locking #
In simple locking, each transaction must first acquire a lock for every shared data object that it intends to read or write before it does any actual reading or writing. It then releases its locks only after the transaction has committed or aborted.
One downside of this method is that applications that discover which objects need to be read by reading other shared data will have to lock every object that they might need to read. Thus, a transaction may end up locking more data objects than needed.
Two-phase locking #
Two-phase locking (or 2PL) differs from simple locking in that a transaction only acquires locks as needed. It works as follows:
- Each transaction acquires locks as it proceeds its operation i.e. it monotonically increases the locks it holds until it requires no more locks. This is the first phase of the process.
- After committing or aborting the transaction, it releases the locks. This is the second phase.
Two-phase locking is prone to deadlocks. A scenario involving two transactions T1 and T2, as shown below, is a real possibility in this protocol.
T1 T2
get(x) get(y)
get(y) get(x)
The system must be able to detect cycles or specify a lock timeout, after which it must abort a blocked transaction. This is an issue even for single-node databases, as long as multiple clients can access the database at the same time. The database must be able to detect deadlocks and abort a transaction when that happens. This post I wrote earlier goes into more detail about 2PL and transaction isolation levels.
Atomic Commit #
So far, we have discussed how concurrency control methods ensure that transactions are serializable. This next challenge, however, is more peculiar to distributed transactions. As stated earlier, the outcome on the individual servers involved in a distributed transaction may vary if one or more servers fail. To guarantee the atomicity property of transactions, we must take extra care to ensure that all the servers involved come to the same decision on the transaction outcome.
Two-phase commit #
Two-phase commit(or 2PC) is a protocol used to guarantee atomicity in distributed transactions. Note that the only similarity it shares with Two-phase locking is in the naming, they do different things.
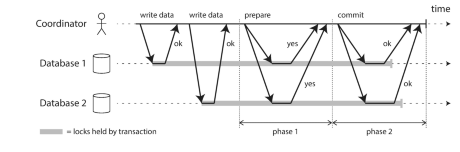
Figure 1: A successful execution of two-phase commit (2PC)\[1\]
Two-phase commit works as follows for a distributed transaction:
-
The database adds another entity, known as the transaction coordinator, to be in charge of the transaction.
-
All the other servers involved in the transaction are called participants.
-
The transaction coordinator first delegates the writes in the transaction to the participants. Each participant creates a nested transaction from the original one, executes the operations which may require holding locks, and sends an acknowledgement to the coordinator.
-
When the coordinator receives the acknowledgement messages, it begins the first phase of the protocol. In this phase, the coordinator sends PREPARE messages to the participants. Each participant then responds to the coordinator by telling it whether it is PREPARED to commit or abort the transaction, based on the outcome of the nested transaction.
-
If any of the participants responds with an abort message, the coordinator decides to abort the whole transaction. The coordinator commits a transaction only if all the participants are ready to commit. The second phase starts when the coordinator creates a COMMITTED or ABORTED record for the overall transaction based on these conditions, and stores that outcome in its durable log. It then broadcasts that decision to the participant nodes as the outcome of the overall transaction.
Note that once a participant promises that it can commit the transaction, it must fulfil that promise regardless of failures. This is done by storing its outcome in a durable log before responding to the coordinator, so it can read from that log on recovery.
The coordinator is a bottleneck #
The major downside of the two-phase commit protocol is if the coordinator fails before it can broadcast the outcome to the participants, the participants may get stuck in a waiting state. A participant that has indicated that it's prepared to commit cannot decide the outcome of the transaction on its own, as another participant may be prepared to abort. Also, a stuck participant cannot decide on its own to abort the transaction, because the coordinator might have sent a COMMIT message to another participant before it crashed.
This is not ideal because the participants may hold locks on shared objects while they are stuck in the waiting state, and thus may prevent other transactions from progressing.
We can improve the fault tolerance of 2PC by integrating it with a consensus algorithm, which will get discussed next.
Two-phase commit and Raft #
Consensus algorithms like Raft solve a different problem from atomic commit protocols. We use Raft to get high availability by replicating the data on multiple servers, where all servers do the same thing. This differs from two-phase commit in that 2PC does not help with availability, and all the participant servers here perform different operations. 2PC also requires that all the servers must do their part, unlike Raft, which only needs a majority.
However, we can combine the two-phase commit protocol with a consensus algorithm as shown below.
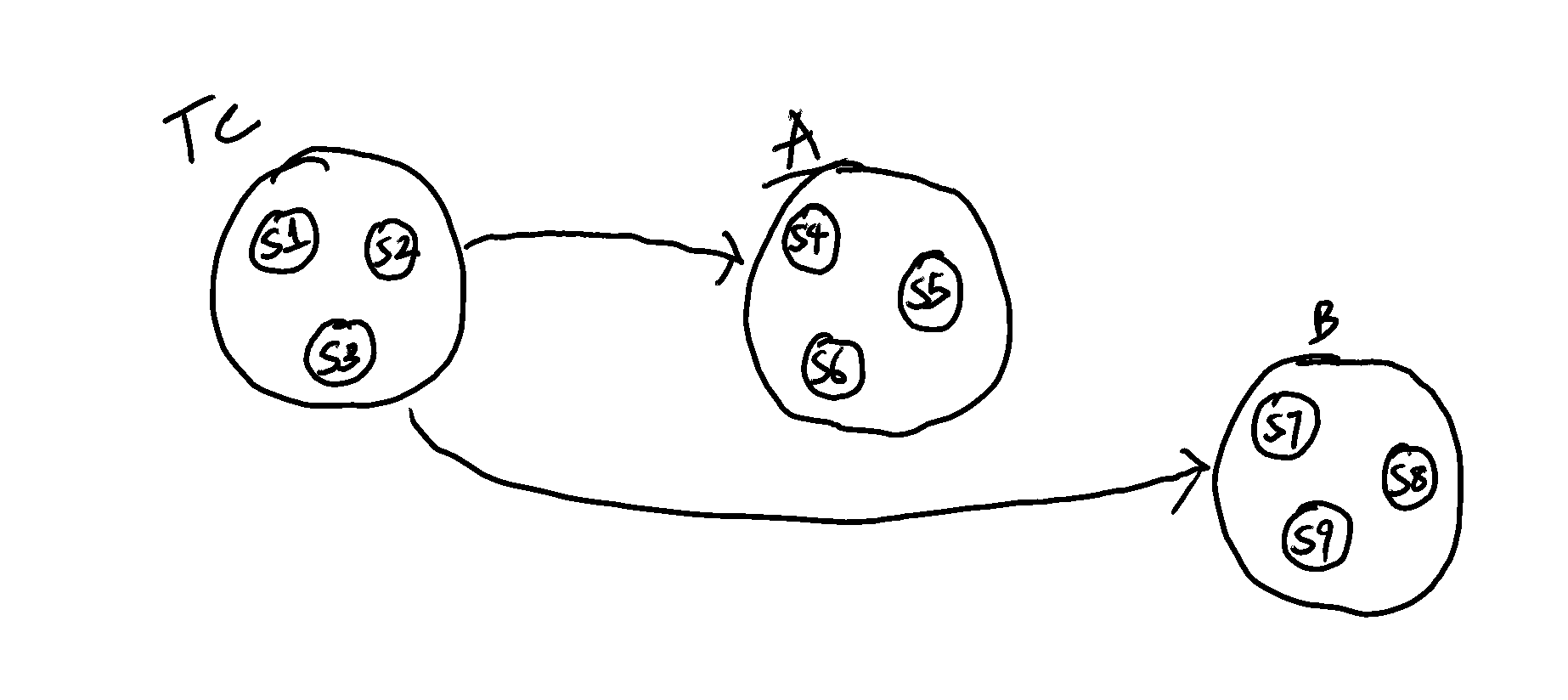
Figure 2: Using 2PC with a distributed consensus algorithm
In Figure 2, the transaction coordinator(Tc) and the participants(A and B) each form a Raft group with three replicas. We can then perform 2PC among the leaders of each Raft group. This way, we can tolerate failures and still make progress with the system, as Raft will automatically elect a new leader. The next lecture will be on Google Spanner, which combines 2PC with the Paxos algorithm.
[1] By Martin Kleppmann in Designing Data-Intensive Applications.
Further Reading #
- Chapter 9 of Principles of Computer System Design: An Introduction, Part I. by Jerome H. Saltzer and M. Frans Kaashoek
- Chapters 7 and 9 of Designing Data-Intensive Applications by Martin Kleppmann.
- Lecture 12: Distributed Transactions - MIT 6.824 Lecture Notes.
- I've gone into more detail about 2PC in another post.