MIT 6.824: Lecture 14 - Optimistic Concurrency Control
· 9 min readThis lecture on optimistic concurrency control is based on a 2015 paper from Microsoft Research describing a system called FaRM. FaRM (Fast Remote Memory) is a main memory computing platform that provides distributed transactions with strict serializability, high performance, durability and high availability.
FaRM takes advantage of two hardware trends to provide these guarantees:
-
Using Remote Direct Memory Access (RDMA) for faster communication between servers.
-
An inexpensive approach to providing Non-volatile Random Access Memory (NVRAM).
In this post, I'll explain how FaRM uses these techniques to perform faster and yield greater throughput than Google Spanner for simple transactions.
Table of Contents
Overview #
The FaRM database is intended for a setup where all the servers are managed in the same data centre. It partitions data into regions stored over many servers and uses primary/backup replication to replicate these regions on one primary and f backup replicas. With this configuration, a region with f + 1 replicas can tolerate f failures.
FaRM uses ZooKeeper as its configuration manager, which manages the primary and backup servers allocation for each region.
Performance Optimizations #
At a high level, some optimizations and tradeoffs that FaRM makes to provide its guarantees are:
-
The data must fit in the total RAM, so there are no disk reads.
-
It makes use of non-volatile DRAM, so there are no disk writes under normal operations.
-
FaRM's transaction and replication protocol take advantage of one-sided RDMA for better performance. RDMA means a server can have rapid access to another server's RAM while bypassing its CPU.
-
FaRM also supports fast user-level access to the Network Interface Card (NIC).
Let's now learn about these optimizations in greater detail.
Non-volatile RAM #
A FaRM server stores data in its RAM, which eliminates the I/O bottleneck in reading from and writing data to disk. For context, it takes about 200ns to write to RAM, while SSD and hard drive writes take about 100μs and 10ms respectively [1]. Writing to RAM is roughly 500x faster than writing to SSD, and we gain a lot of performance from this optimization.
But by storing data in RAM, we lose the guarantee that our data will survive a power failure. FaRM provides this guarantee by attaching its servers to a distributed UPS, which makes the data durable. When the power goes out, the distributed UPS saves the RAM's content to an SSD using the energy from its battery. This operation may take a few minutes, after which the server shuts down. When the server is restarted, FaRM loads the saved image on the SSD back into memory. Another approach to making RAM durable is to use NVDIMMs, but the distributed UPS mechanism used by FaRM is cheaper.
Note that this distributed UPS arrangement only works in the event of a power failure. Other faults such as CPU, memory, hardware errors, and bugs in FaRM, can cause a server to crash without persisting the RAM content. FaRM copes with this by storing data on more than one replica. When a server crashes, FaRM copies the data from the RAM of one of the failed server's replicas to another machine to ensure that there are always f + 1 copies available, where f represents the number of failures we can tolerate.
By eliminating the bottleneck in accessing the disk, we can now focus on two other performance bottlenecks: network and CPU.
Networking #
At a high level, communication between two computers on a network is as shown in Figure 1 below [2].
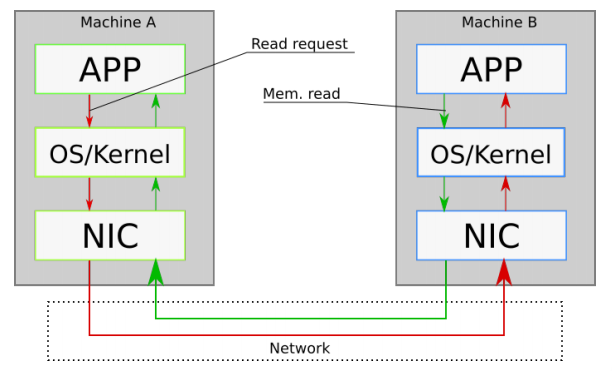
Figure 1 - Setup for RPC between computers on a network
In this setup, we see that communication between two machines A and B on a network goes through the kernel of both machines. This kernel consists of different layers through which messages must pass.
Figure 2 below shows this in more detail.
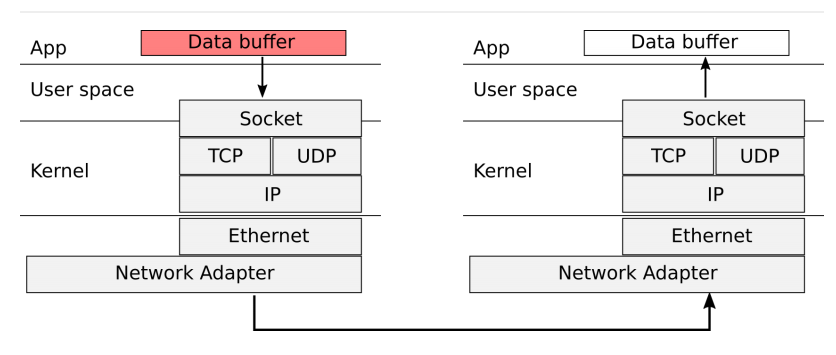
Figure 2 - Networking stack. Message must pass through all the different layers.
This stack requires a lot of expensive CPU operations—system calls, interrupts, and communication between the different layers—to transmit messages from one computer to another, and these slow the performance of network operations.
FaRM uses two ideas to improve this networking performance:
- Kernel bypass: Here, the application interacts directly with the NIC without making system calls or involving the kernel.
- One-sided RDMA: With one-sided RDMA, a server can read from or write to the memory of a remote computer without involving its CPU.
Figure 3 highlights these ideas. In the figure, we see that the CPU of Machine A communicates with the NIC without the kernel involved, and the NIC of Machine B bypasses the CPU to access the RAM.
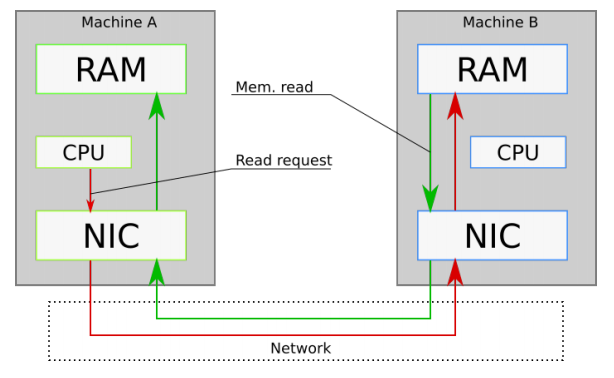
Figure 3 - RDMA and Kernel Bypass
These optimizations made in FaRM to reduce the storage, network, and CPU usage solve most of the performance bottlenecks found in many applications today.
Can we bypass the CPU? #
The transaction protocols we have seen in the systems discussed in earlier lectures like Spanner require active server participation. They need the CPU to answer questions like:
- Is a database record locked?
- Which is the latest version of a record?
- Is a write committed yet?
But one-sided RDMA bypasses the CPU, so it is not immediately compatible with these protocols. How then can we ensure consistency while avoiding the CPU?
The rest of this post details FaRM's approach to solving this challenge.
Optimistic and pessimistic concurrency control #
To recap an earlier post, two classes of concurrency control exist for transactions:
-
Pessimistic: When a transaction wants to read or write an object, it first attempts to acquire a lock. If the attempt is successful, it must hold that lock until it commits or aborts. Otherwise, the transaction must wait until any conflicting transaction releases it lock on the object.
-
Optimistic: Here, we can run a transaction that reads and writes objects without locking until commit time. The commit stage requires validating that no other transactions changed the data in a way that conflicted with ours. If there's a conflict, our transaction gets aborted. Otherwise, the database commits the writes.
FaRM uses Optimistic Concurrency Control (OCC) which reduces the need for active server participation when executing transactions.
FaRM machines maintain logs #
Before going into the details of how transactions work, note that each FaRM machine maintains logs which they use as either transaction logs or message queues. These logs are used to communicate between sender-receiver pairs in a FaRM cluster. The sender appends records to the log using one-sided RDMA writes, which the receiver acknowledges via its NIC without involving the CPU. The receiver processes records by periodically polling the head of its log.
How transactions work #
FaRM supports reading and writing multiple objects within a transaction, and guarantees strict serializability of all successfully committed transactions.
Each object or record in the database has a 64-bit version number which FaRM uses for concurrency control and an address representing its location in a server.
Any application thread can start a transaction and this thread then becomes the transaction coordinator. This transaction coordinator communicates directly with replicas and backups as shown in the figure below.
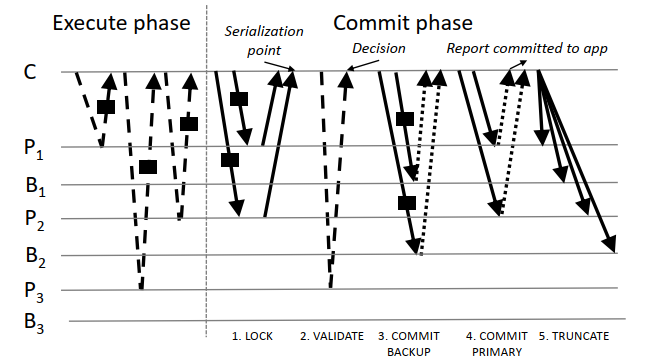
Figure 4 - FaRM commit protocol with a coordinator C, primaries on P1; P2; P3, and backups on B1; B2; B3. P1 and P2 are read and written. P3 is only read. We use dashed lines for RDMA reads, solid ones for RDMA writes, dotted ones for hardware acks, and rectangles for object data.
Execute #
In the Execute phase, the transaction coordinator uses one-sided RDMA to read objects and buffers changes to objects locally. These reads and writes happen without locking any objects— optimism. The coordinator always sends the reads for an object to the primary copy of the containing region. For primaries and backups on the same machine as the coordinator, it reads and writes to the log using local memory accesses instead of RDMA.
During transaction execution, the coordinator keeps track of the addresses and versions of all the objects it has accessed. It uses these in later phases.
After executing the specified operations within a transaction, FaRM starts the commit process using the steps discussed next. Note that I'll detail them in a different order from Figure 4, but it will make sense why.
Lock #
The first step in committing a transaction that changes one or more objects is that the coordinator sends a LOCK record to the primary of each written object. This LOCK record contains the transaction ID, the IDs of all the regions with objects written by the transaction, and addresses, versions, and new values of all objects written by the transaction that the destination is primary for. The coordinator uses RDMA to append this record to the log at each primary.
When a primary receives this record, it attempts to lock each object at its specified version. This involves using an atomic compare-and-swap operation on the high-order bit of its version number—which represents the "lock" flag. The primary then sends back a message to the coordinator reporting whether all the lock attempts were successful. Locking will fail if any of these conditions is met:
- Another transaction has locked the object.
- The current version of the object differs from what the transaction read and sent in its LOCK record.
A failed lock attempt at any primary will cause the coordinator to abort the transaction by writing an ABORT record to all the primaries so they can release any held locks, after which the coordinator returns an error to the application.
Commit primaries #
If all the primaries report successful lock attempts, then the coordinator will decide to commit the transaction. It broadcasts this decision to the primaries by appending a COMMIT-PRIMARY record to primaries' logs. This COMMIT-PRIMARY record contains the ID of the transaction to commit. A primary processes the record by copying the new value of each object in the LOCK record for the transaction into memory, incrementing the object's version number, and clearing the object's lock flag.
The coordinator does not wait for the primaries to process the log entry before it reports success to the client, it only needs an RDMA acknowledgement from one primary that the entry has been received and stored in the NVRAM. We'll see why this is safe later.
Validate #
The commit steps so far describe FaRM's protocol when a transaction modifies an object. But in read-only transactions, or for objects that are read but not written by a transaction, the coordinator does not write any LOCK records.
The coordinator performs commit validation in these scenarios by using one-sided RDMA reads to re-fetch each object's version number and status of its lock flag. If the lock flag is set or the version number has changed since the transaction read it, the coordinator aborts the transaction.
This optimization avoids holding locks in read-only transactions, which speeds up their execution.
Lock + Validate = Strict Serializability #
Under non-failure conditions, the locking and validation steps guarantee strict serializability of all committed FaRM transactions. They ensure that the result of executing concurrent transactions is the same as if they are executed one after the other, and the order that produces the result is consistent with real time.
Specifically, the steps guarantee that for a transaction:
-
If there were no conflicting transactions, the object versions it read won't have changed.
-
If there were conflicting transactions, it will see a changed version number or a lock on an object it accessed.
Let's see how this plays out using some examples from the lecture.
Examples #
In this first example, we have two simultaneous transactions, T1 and T2.
T1: Rx Ly Vx Cy
T2: Ry Lx Vy Cx
(Where L and V represent the Lock and Validate stages)
Here, the LOCKs in both operations will succeed while the VALIDATEs will fail. The validation for x will fail in T1 because its lock bit has been set by T2 and Vy will fail in T2 because y has been locked by T1. Both transactions will then abort, which satisfies our desired guarantee.
This next example has a similar setup.
T1: Rx Ly Vx Cy
T2: Ry Lx Vy Cx
In the example, T1 will commit while T2 will abort, since T2's Vy will see either T1's lock on y or a higher version of y.
Fault Tolerance - Commit backups #
Unfortunately, the protocol described above is not enough to guarantee serializability when there are system failures.
Recall that the coordinator needs acknowledgement from only one primary for the COMMIT-PRIMARY record before its reports success to clients. This means that a committed write could be visible as soon as the COMMIT-PRIMARY is sent, since that primary will write the data and unlock the objects involved.
Thus, we could have a scenario where a transaction fails after it has committed on one primary but before committing on the others. This violates transaction atomicity, which requires that if a transaction succeeds on one machine, it must succeed on all the others.
FaRM achieves this atomicity through the use of COMMIT-BACKUP records. While LOCK records tell the primaries the new values, COMMIT-BACKUP records give the same information to the backups.
The key thing to note is that before sending the COMMIT-PRIMARY records, the coordinator sends a COMMIT-BACKUP record to the backups of the primaries involved in a transaction and waits for acknowledgement that they are persisted on all the backups. This COMMIT-BACKUP record contains the same data as the LOCK record for a transaction.
By also waiting for acknowledgement that a COMMIT-PRIMARY record has been stored from at least one primary, the coordinator ensures that at least one commit record survives any f failures for transactions reported as committed to the application.
Truncate #
The coordinator truncates the logs at primaries and backups after receiving acknowledgements from all the primaries that they have stored a commit record.
Conclusion #
FaRM is innovative in its use of optimistic concurrency control to allow fast one-sided RDMA reads while providing strict serializability for distributed transactions. I recommended reading the Spanner post for an alternative approach to distributed transactions.
As far as I know, though, FaRM is still a research prototype and has not been deployed in any production systems so far. For all of its performance optimizations, FaRM is limited because its data must fit in the total RAM and replication occurs only within a data centre. Its API is also restrictive, as it does not support SQL operations like Spanner does.
I've also omitted some implementation details here on failure detection and reconfiguring the FaRM instance after recovery, but I hope you've learned enough to pique your interest in the topic.
[1]: Storage with the speed of memory? XPoint, XPoint, that's our plan
[2]: Lecture Notes on Distributed Systems(Fall 2017) by Jacek Lysiak
Further Reading #
- No compromises: distributed transactions with consistency, availability, and performance - Original FaRM paper.
- Lecture 14: FaRM, Optimistic Concurrency Control - MIT 6.824 lecture notes.
- Path of a Packet in the Linux Kernel Stack by Ashwin Kumar Chimata.
- Serializable Snapshot Isolation - Earlier post on an OCC method of transaction isolation.