MIT 6.824: Lecture 10 - Cloud Replicated DB, Aurora
· 6 min readAmazon Aurora is a distributed database service provided by AWS. Its original paper describes the considerations in building a database for the cloud and details how Aurora's architecture differs from many traditional databases today. This post will explain how traditional databases work and then highlight how Aurora provides great performance through quorum writes and by building a database around the log.
Table of Contents
How databases work (simplified) #
Traditional relational databases comprise many units that work together: the transport module which communicates with clients and receives queries, the query processor which parses a query and creates a query plan to be carried out, the execution engine which collects the results of the execution of the operations in the plan, and the storage engine.
The storage engine interacts with the execution engine and is responsible for the actual execution of the query. Databases typically make use of a two-level memory hierarchy: the faster main memory (RAM) and the slower persistent storage (disk). The storage engine helps to manage both the data in memory and on disk. The main memory is used to prevent frequent access to the disk.
The database organizes its records into pages. When a page in the database is about to be updated, the page is first retrieved from disk and stored in a page cache in memory. The changes are then made against that cached page until it is eventually synchronized with the persistent storage. A cached page is said to be dirty when it has been updated in memory and it needs to be flushed back on disk.
Let's consider the example of a database transaction which involves updating two records: A and B. It will involve the following steps:
- The data pages on which the records are stored are located on disk and loaded into the page cache.
- The database then generates redo log records from the changes that will be made to the pages. A redo log record consists of the difference between the before-image of a page and its after-image as a result of any changes made. These changes are then applied to the cached pages.
- When the transaction commits, these log records are durably persisted to a write-ahead log stored on disk. The modified data pages may still be kept in memory and written back to disk later. In the event of a crash that leads to the loss of the in-memory data, the write-ahead log helps with recovery by ensuring that the database can still apply the logged changes to the on-disk structure.
- After a period, the dirty pages are written back to disk.
The storage engine has a buffer manager for managing the page cache. Besides the buffer manager, it is made up of other components such as the transaction manager which schedules and coordinates transactions, the lock manager which prevents concurrent access to shared resources that would violate data integrity, and the log manager which keeps track of the write-ahead log.
Note: I've written another post that goes into more detail about how databases work.
Aurora #
Aurora decouples the storage layer #
In a monolithic database setup, the database runs on the same physical machine as the storage volume. However, in many modern distributed databases, the storage layer is decoupled from the database layer and replicated across multiple nodes to achieve scalability and resilience. While this is helpful for better fault tolerance, the downside is that communication between the database layer and the storage layer now happens via the network and the bottleneck lies there. Each write to the database could involve multiple write operations at the database layer, in what's known as write amplification, and all the communication between the database layer and the storage layer will happen over the network.
For example, the figure below illustrates write amplification. The setup shown is a synchronous mirrored MySQL configuration which achieves high availability across data centres. Each availability zone(AZ) has a MySQL instance with networked storage on Amazon Elastic Block Store (EBS), with the primary instance being in AZ1 and the standby instance in AZ2. There is also a primary EBS volume which is synchronized with the standby EBS using software mirroring.
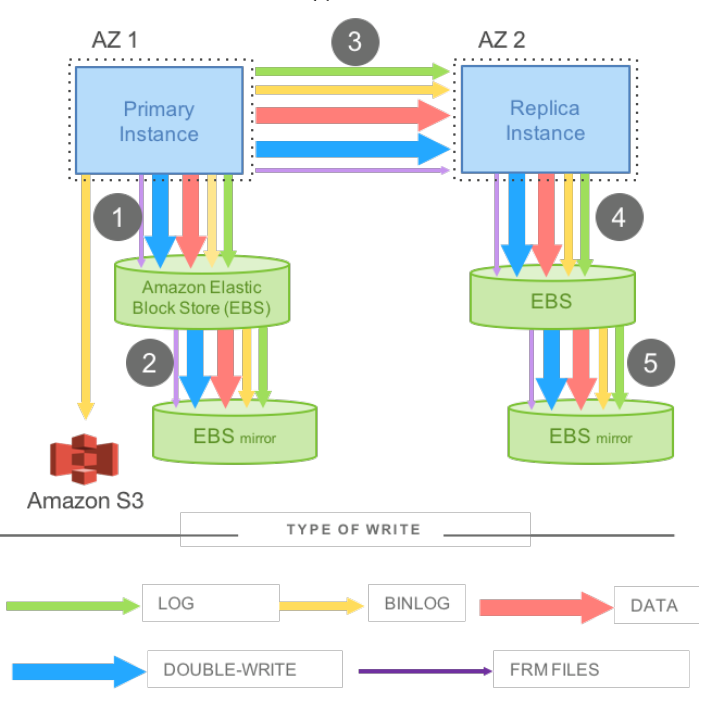
Figure 1 - Network IO in mirrored MySQL
From the paper:
Figure 1 shows the various types of data that the engine needs to write: the redo log, the binary (statement) log that is archived to Amazon Simple Storage Service (S3) in order to support point-in-time restores, the modified data pages, a second temporary write of the data page (double-write) to prevent torn pages, and finally the metadata files.
This model shown in the setup is undesirable for two major reasons:
- There is a high network load involved in moving the data pages around from the database instance to the storage volumes.
- All four EBS volumes must respond for a write to be complete. This means that the process can be slowed down by at least one faulty node, which makes it less fault tolerant.
Aurora tackles these problems by offloading the processing of the redo log to the storage engine and through quorum writes. The next few sections will go into more detail about these optimizations.
The log is the database #
As described above, a traditional database generates a redo log record when it modifies a data page in a transaction. The log applicator then applies this log record to the in-memory before-image of the page to produce the after-image. This log record must be persisted on disk for the transaction to be committed, but the dirty data page can be written back to disk at a later time.
Aurora reworks this process by having the log applicator at the storage layer in addition to the database layer. This way, no pages are ever written from the database layer to the storage layer. Redo log records are the only writes that ever cross the network. These records are much smaller than data pages and hence reduce the network load. The log applicator generates any relevant data pages at the storage tier.
Note that the log applicator is still present at the database layer. This way, we can still modify cached data pages based on the redo log records and read up-to-date values from them. The difference now is that those dirty pages are not written back to the storage layer; instead, only the log records are written back. There is a caveat on what redo records can be applied by the log applicator in the database layer, and that will be discussed in the next section.
Aurora uses quorum writes #
Aurora partitions the storage volume into fixed-size segments of size 10 GB. Each partition is replicated six ways into Protection Groups (PGs). A Protection Group is made up of six 10GB segments organized across three availability zones, with two segments in each availability zone. Each write must achieve a quorum of votes from 4 out of 6 segments before it is committed. By doing this, Aurora can survive the failure of an availability zone or any other two nodes without losing write availability.
The database layer generates the fully ordered redo log records and delivers them to all six replicas of the destination segment. However, it only needs to wait for acknowledgement from 4 out of the 6 replicas before the log records are considered durable. Each replica can apply its redo records using its log applicator.
The paper's authors ran an experiment to measure the network I/O based on these optimizations and compared it with the setup in Figure 1. The results are shown in the table below.
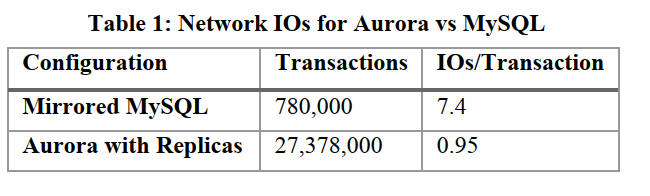
Aurora performed significantly better than the mirrored MySQL setup. From the paper:
Over the 30-minute period, Aurora was able to sustain 35 times more transactions than mirrored MySQL. The number of I/Os per transaction on the database node in Aurora was 7.7 times fewer than in mirrored MySQL despite amplifying writes six times with
Aurora and not counting the chained replication within EBS nor the cross-AZ writes in MySQL. Each storage node sees unamplified writes, since it is only one of the six copies, resulting in 46 times fewer I/Os requiring processing at this tier. The savings we obtain by writing less data to the network allow us to aggressively replicate data for durability and availability and issue requests in parallel to minimize the impact of jitter.
The database instance is replicated too #
In Aurora, the database tier can have up to 15 read replicas and one write replica. In addition to the storage nodes, the log stream generated by the writer is also sent to the read replicas. The writer does not wait for an acknowledgement from the read replicas before committing a write, it only needs a quorum from the storage nodes.
Each read replica consumes the log stream and uses its log applicator to modify the pages in its cache based on the log records. By doing this, the replica can serve pages from its buffer cache and will only make a storage IO request if the requested page is not in its cache.
Aurora does not need quorum reads #
In Aurora, the database layer directly feeds log records to the storage nodes and keeps track of the progress of each segment in its runtime state. Therefore, under normal circumstances, the database layer can issue a read request directly to the segment which has the most up-to-date data without needing to establish a read quorum.
However, after a crash, the database layer needs to reestablish its runtime state through a read quorum of the segments for each protection group.
Conclusion #
According to this post, Aurora was the fastest-growing service in AWS history as of March 2019. Its architecture has enabled it to provide performance and availability comparable to other commercial-grade databases at a cheaper cost. The paper goes into more detail about how the read and write operations work across the segments and the recovery procesws. As an aside, this has been my most difficult paper to read so far, and it's one where the lecture video (and rereading the paper multiple times!) really helped to clarify stuff.
Further Reading #
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases - The original paper.
- Lecture 10: Database logging, quorums, Amazon Aurora - MIT 6.824 lecture notes.
- Database Internals by Alex Petrov.
- Amazon Aurora ascendant: How we designed a cloud-native relational database by Werner Vogels.
- Amazon Aurora: Design considerations for high throughput cloud-native relational databases from The Morning Paper.