Data Storage on Your Computer's Disk - Part 1
· 9 min readTable of Contents
- Background
- A bit about data storage on disk
- Conclusion/Next Steps
- Open Question I Still Have
- Further Reading
Background #
You may skip this story and go straight to the main post.
I've been reading Martin Kleppmann's great book on "Designing Data-Intensive Applications" for some time now.
In the third chapter of the book which deals with the storage and retrieval of data, Martin explains a lot about what database indexes are, how they work, the different types of indexing structures we have, and so on. I found this interesting to read, but I kept wondering how or if those database indexes differed from the underlying data being stored. He did a good job of explaining this, but I found it difficult to visualize how these indexing structures are actually laid out on disk with data.
This led me on a journey of naive Google searches like: "is the lsm tree an index or a storage engine" and "is the b tree simply an index". In the end, I think I have a decent understanding of how database indexes are related to the data they store, and how those get represented on disk. I aim to detail what I have learned about how data is stored in these series of posts.
This post is an introduction and will focus on how data is represented on your computer's disk without indexes.
Starting off with a few disclaimers:
- A lot of the concepts I'll discuss here are based on my knowledge of how SQLServer works. Don't be discouraged if you haven't used SQLServer though, I haven't either! I just found that the resources for SQLServer were more accessible to me than any other set of resources. My guess (and hope) is that though some of the implementation details may differ from other Relational Database Management Systems (think MySQL, PostgreSQL, etc), the underlying concepts are similar.
- I'm no expert in any of these topics so please reach out to via the feedback form if you spot any errors in my understanding that you would like to correct.
A bit about data storage on disk #
I'll be using some words repeatedly in this section so I thought it'll be a good idea to list them here as a reference. I'll explain how they fit together in more detail later on, so stay with me!
- Disk I/O Operations: These are read and write operations that involve accessing your computer's physical disk.
- Records: A row in your database table maps to a record on your computer's disk. Records can be of various sizes depending on the data contained in a row. There are different types of records, such as data records - say for storing an individual book in a database of books, index records, and records for other metadata about the database.
- Pages: A page consists of many records. Pages have a fixed size which can be 4KB, 8KB, 16KB, etc. Fixed here means that a 4KB page cannot be expanded to fit more data when full. SQLServer pages are typically 8KB in size. Two of the most popular page types are Data pages and Index pages. As you can imagine, data pages store data records and index pages store index records. We'll learn more about these page types in this series.
Records #
When you add a new row to a database table using SQL, that row is converted internally to a record. Think of a record as an array of bytes, where each byte or group of bytes stores information about the record. The information stored in a group of bytes could be:
- The type of the record: data, index, or other metadata.
- Whether the inserted row has columns with null values or columns have fixed or variable length data types.
- Where each column's data starts and ends in the array.
- The actual data encoded in bytes, divided into separate sections depending on whether the data type used for storing the data has a fixed length or a variable length.

Figure 1 - Inexact representation of a database record.
Notes:
- A more precise representation of what a record looks like can be found here. The purpose of the diagram above is to help visualize the structure on a high level.
- The "Information about columns..." here typically includes:
- The number of columns that match the condition i.e. fixed length, null or variable length.
- The positions of those columns; where those columns start and end. This makes it easier to query the data for a particular column.
Pages #
When this record is created, it is added to a page. Databases tend to work with pages. A page is the smallest unit of data that a database will load into a memory cache. Let's back up a little and talk about why pages are important.
A database table could have billions of records or more. Storing these records side by side in a file could be a nightmare to manage. There will be some added complexity around storing and retrieving a record. Records are organized into pages to make them easier to work with.
Imagine that a database needs to retrieve millions of records from disk and load them into memory. It would be difficult to determine how much space to allocate in memory for this operation. With pages, this becomes easier to manage since they are of a fixed length.
Think of pages in this case like pages in a notebook. A notebook page is made up of several lines of text. This organization makes it easier to find a line on a page once you have the page number. It also means that if you tear out a page from a notebook, you can read all the lines on that page without having to refer to the notebook multiple times. Pages in the context of disk storage minimize the number of disk I/O operations that will be needed to retrieve a record or a set of records.
Two key things to note are these:
- When you add a new record (row) or update an existing record in your database table, that change is reflected on a data page which exists in an in-memory cache.
- When you want to read a record from your database table, the system first checks if the page exists in the cache before hitting the disk otherwise.
The reason for this is simple: it is faster and less resource-intensive for the CPU to access data in the main memory i.e. in-memory cache than it is to go the disk to fetch data. However, this is not without its drawbacks. Unlike data stored in memory, data stored on your hard disk is durable. When you shut down your laptop, you still have the data on your hard disk. That's unfortunately not the case for data in the main memory.
You may then wonder: If a record that I insert or update is stored on a page located in the main memory, and data is lost if the computer is switched off, how are my changes prevented from being lost if something bad happens?
Good question! I'll address this soon, but not before I talk about some principles that guide how pages are loaded from the disk into the in-memory cache. These include:
a) Temporal Locality: Temporal locality means that pages are loaded in-memory based on the likelihood that a recently accessed page will be accessed again soon. It means that if you make a query that happens to fetch some data pages from disk, those data pages will be stored in memory for as long as possible to prevent having to go to the disk to fetch them again.
b) Spatial Locality: This works based on the prediction that if a page is loaded in memory, the pages that are stored physically close to that page on disk will likely be accessed soon. As a result, some pages are 'pre-fetched' ahead of when they are actually used. It means that if you run a query that fetches a page which has records with IDs that range from 1-30, the page which has records from 31-60 will also likely be loaded alongside it to prevent a subsequent trip to the disk.
These principles help to minimize the number of disk I/O operations needed.
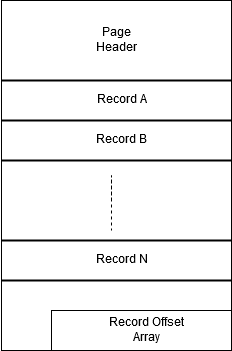
Figure 2 - Structure of a Database Page
Notes:
- The Page Header contains information about the page like: how many records it contains, how much space it has left, what table a page belongs to etc.
- The Record Offset array helps to manage the location of the records on a page. Each 'slot' in the array points to the beginning of a record, and helps to locate where the record is physically stored on disk.
Writeback #
Recall that saved records are first added to a page located in an in-memory cache. Writeback is the process by which pages located in-memory are written back to disk. When a page has two copies: one in memory and the other on disk, and the more recent page (the one in-memory) has been modified, the page is referred to as being dirty. The content in-memory differs from what is on disk, and the content on disk needs to be updated since it is the durable data store.
Now, I do not know all the details about when or how this writeback process is triggered. My understanding is that it happens periodically, but I believe there's more to that.
I'm aware that I haven't answered the question I teased earlier about how databases prevent data from being lost, if data is initially saved in a temporary location. This section might also provoke a similar question from you:
What if the computer is switched off before writeback happens?
I've teased you enough, so I'll address that in the next section.
Write-ahead Logs #
Write-ahead logs are used in a number of database systems ranging from relational databases like PostgreSQL to in-memory datastores like Redis. A log is an append-only file. It means that when you add a record to a log, it's placed at the bottom of the log i.e. adding records is sequential. This has an advantage of faster writes than say if the records in the file are sorted, as you only need to keep track of the latest record in the log when you want to insert something. There's the drawback that it's less efficient to find a specific record in the log if records are not sorted, as you may end up checking each line in a log of a billion lines! Logs are not typically used this way though, and there's typically an additional structure involved for this purpose (hint: It's called an index).
I'm not giving you the full story about logs and other contexts in which they are used, but for the purpose of this post, the key thing to note is that they are append-only files, and writes are sequential.
Now, recall that I said that database writes (which involve creating, updating, or deleting a record) are first written to a page that exists in memory, making them likely to get lost in the event of a system crash. Well, that's not quite the full story. In many database systems, writes are also logged to a special file known as a write-ahead log. This log describes what changes happened on what pages. The log file is persisted to the disk (aka. permanent storage) when the database writes are completed. This way, if your computer crashes before the in-memory pages have been written back to the disk, the lost changes can be restored from the log file. Any change that has been recorded on the log file but is not reflecting in the database can be restored.
To explain why using a write-ahead log is beneficial over writing the pages directly to the disk, I'll introduce one final concept known as Transactions.
Transactions #
Think of a transaction as a group of one or more database operations which act independently of other groups. If at least one operation in a group fails, the whole group is declared as a failure and then the transaction aborts. If all the operations in a group complete successfully, then the transaction commits.
To make this more practical, imagine you have a 'Cars' table in your database, you could be performing the following operations in one transaction:
- Inserting 5 new cars into the table
- Updating the prices of 3 cars
- Deleting cars manufactured before 2010
If at least one of these operations fails, say one of the five insertions violates a uniqueness constraint, the whole transaction fails - including the updates and deletions!
Without this concept of transactions, if there's a failure in the middle of a number of database changes, it's difficult to keep track of which changes have happened, and it could leave you with incorrect data if you make some changes twice.
Going back to why writing to a write-ahead log is beneficial over writing data pages directly to disk, the advantage that a write-ahead log provides is that it is written to disk only once per transaction, which is when the transaction is committed. Contrast this with a situation where data pages are written directly to disk immediately; if a transaction involves changing multiple data pages, each data file will need to be written to disk before a write is successful, which will slow down the performance of the database. A Write-ahead log greatly reduces the number of disk writes needed for database operations.
Conclusion/Next Steps #
I've only scratched the surface of this and there are still questions I haven't answered like: What determines what page a record is stored on? What determines how a page is laid out on disk? How does the database know what pages to search for a record? And more...
I'll answer those in the next few posts about database indexing structures: B-Trees and LSM Trees in particular.
Open Question I Still Have #
- What rules govern when writeback is triggered? Does the application developer just set an interval for that to happen?
Further Reading #
I'll divide this section by different topics if you're interested in going into more detail.
General Overview of Distributed Systems #
- Designing Data-Intensive Applications by Martin Kleppmann- I'm about 80% done with the book and I've learned so much from it already. I'll highly recommend it.
Records & Pages #
- SQL Server Storage Internals by Mark S Rasmussen- I really enjoyed this post as it helped me make sense of how information is stored on records and pages. It was also useful for understanding indexes better.
- Spatial and Temporal Locality for Dummies by Adam Zerner.
- Toward less-annoying background writeback by Jonathan Corbet.
- On Disk IO, Part 1: Flavors of IO by Alex Petrov - I found the bit on the writeback process useful.
- What is a slot array? by Jamesask.
Write-ahead Logs #
- Write-ahead Logging from the PostgreSQL documentation.
- Append-only File Persistence from RedisLabs.
- How to Make System Logs Append-Only from WildWildWolf.
Last updated on 19-06-2020.