MIT 6.824: Lecture 20 - Blockstack
· 7 min readThe final post in this lecture series is about Blockstack. Blockstack is a network for building decentralized applications based on blockchain. I find the idea of decentralized applications appealing because of its promise to give users more ownership and control of their data.
Blockstack is also interesting as it's a non-cryptocurrency use of blockchain, which I covered in the previous post. I'll start this post with an overview of how a decentralized application might work, before describing Blockstack's approach.
Table of Contents
Decentralization #
Some of the most popular applications today like Gmail, Facebook, and Twitter are run by companies which own and manage their users' data and expose an interface for users to access their data. These apps are centralized in that the companies that run them store and manage all the user data.
While this model has been very successful for both the companies and users, it has come with its downsides:
- Employees of these companies can snoop on private user data.
- Most users have to go through the application's UI to access their data, and they can only do what the UI supports with their data.
For these reasons and more, there has been a trend towards building decentralized applications which move ownership and agency of data back into users' hands.
A decentralized architecture #
In centralized applications, there is a tight coupling between the application code and the way they store data. For example, the Twitter app knows how to interact with Twitter's databases. But in a decentralized app, we can separate the app code from user data.
In this architecture, we can have a storage service that is independent of the applications that interact with it. This service will store data on a per-user basis instead of a per-app basis, and each user on the network can own and control their data.
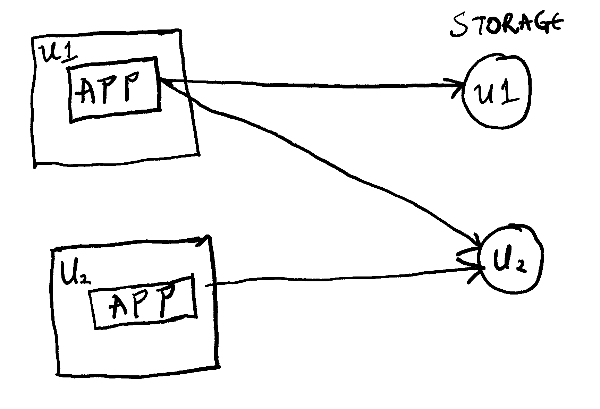
Figure 1: A decentralized architecture.
In designing this architecture, the storage service must meet the following requirements:
- General-purpose. Similar to the file system on your computer, it must have an API that allows multiple applications to interact with it.
- Cloud-based, so users can access their data from anywhere.
- Fully controllable by a user. It must support mechanisms for securing the data and controlling who can access it.
- Supports sharing between users for apps where one user might read another user's information.
This architecture will provide the following benefits to users:
- Better ownership and control over their data and how it's used.
- Better security and data privacy, assuming app owners implement end-to-end encryption.
- Improved ability for users to switch between similar applications, since data storage is independent of the applications.
A decentralized application #
With this architecture, using an application like Facebook will involve:
- Running the Facebook app, which will have no associated servers, on your computer.
- The Facebook app reading from and writing to your data store.
- The Facebook application reading from your friends' data stores to display their information on your feed.
The key thing here is that the application running on your computer contains all the logic it needs to interact directly with a general-purpose storage service, with no servers involved.
This is how many downloaded applications on your computer work, in that they interact with your local file system without needing to talk to a server.
Decentralization can be painful #
This decentralized architecture comes with its limitations for both users and developers. It can be significantly more challenging for developers to build decentralized apps, especially since a per-user general-purpose storage service is less flexible than a dedicated database.
Users may not want to manage the security of their data, especially when it involves more complex security mechanisms. There's also the social challenge of convincing users to even consider using decentralized apps, especially since the current centralized architecture works so well.
Blockstack #
Blockstack is an open-source approach to building a decentralized internet, using blockchain as the underlying infrastructure. Similar to the architecture discussed so far, each user on the Blockstack network has their private data store, and applications running on the network interact with these data stores.
According to the 2017 paper which this lecture is based on, the authors built Blockstack with three design goals:
- Decentralized Naming & Discovery: End-users should be able to (a) register and use human-readable names and (b) discover network resources mapped to human-readable names without trusting any remote parties.
- Decentralized Storage: End-users should be able to use decentralized storage systems where they can store their data without revealing it to any remote parties.
- Comparable Performance: The end-to-end performance of the new architecture (including name/resource lookups, storage access, etc.) should be comparable to the traditional internet with centralized services.
To achieve these goals, Blockstack's architecture comprises the different components shown below.
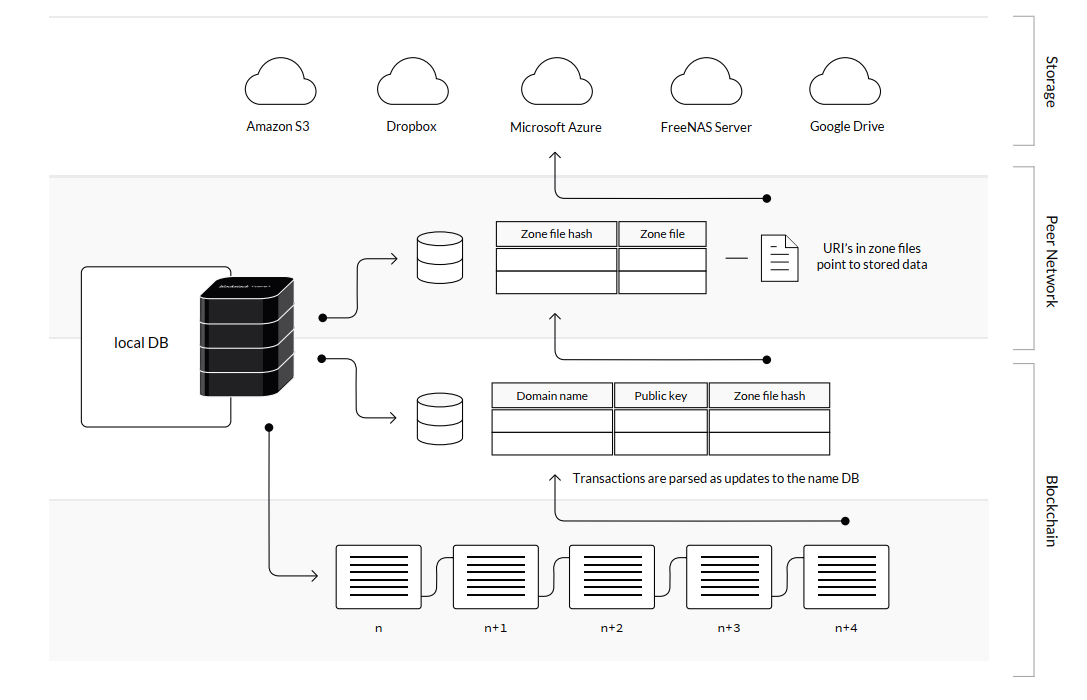
Figure 2: Overview of the Blockstack architecture.
The paper's authors further divide these components into layers. I'll describe these layers and how they all fit together soon.
Naming #
Names are important in Blockstack for identifying users, applications, and domains. A Blockstack name can map to a user's public key, the location of their data store, an IP address, etc.
When designing Blockstack, there were three properties that the authors desired for a name:
- Human-readable: Instead of using a hash to identify users, Blockstack uses human-readable names to provide a good user experience.
- Globally unique: There should be only one owner of the name in the network.
- Decentralized allocation: There should be no central service in charge of allocating names.
According to the paper, before the invention of blockchains, it was only possible to get two of these three properties at a time. This is a computer science limitation called Zooko's triangle. For example:
- Email addresses are unique and human-readable but not decentralized as the company you register with controls the namespace.
- Public keys are unique and decentralized as users can generate them without a central service, but they are not human readable.
- The names on your contact list are decentralized and human-readable, but not unique.
The next section will cover how a blockchain helps achieve these properties.
The Blockchain #
Blockstack uses a blockchain layer to get all the three desired properties of names. This layer comprises two components: the Bitcoin blockchain and a virtualchain, which work together to form the Blockchain Naming System (BNS). The BNS replaces DNS in the network, except that there are no central root servers involved.
Claiming a name in BNS requires Bitcoin transactions, which Blockstack embeds with information about the name. Since the Bitcoin blockchain produces an ordered chain of blocks, we can determine who claimed a name first and ensure that names are unique. Using the blockchain to claim names also means that allocation is decentralized by design.
For example, if you're claiming a new Blockstack name, the associated Bitcoin transaction will contain the following:
-
Your desired name.
-
Your public key.
-
The hash of a BNS zone file. Blockstack creates a zone file for each name in the network and this file contains the routing information for that name, i.e., what resource the name points to.
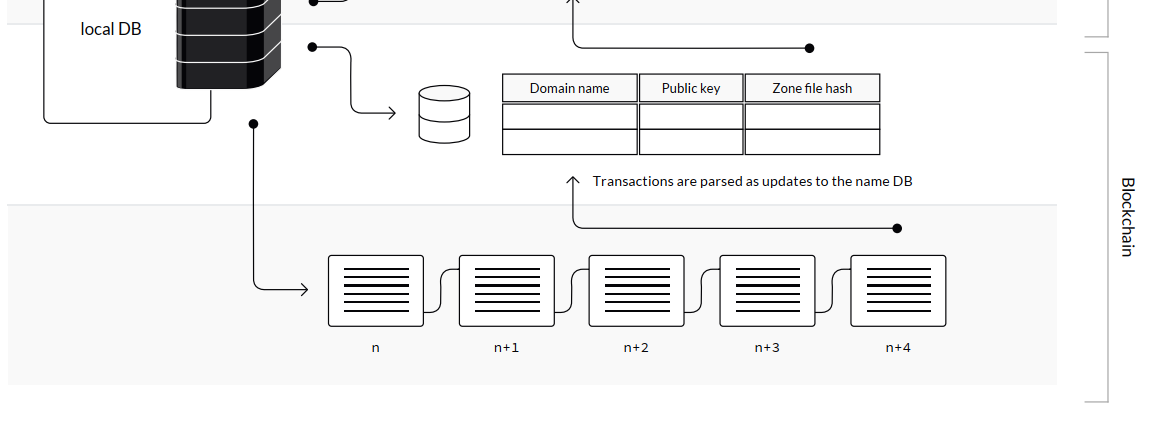
Figure 3: The Blockchain layer.
The virtualchain component sits on the Bitcoin blockchain and parses the transaction records to create name records from the information on the Blockchain. It then stores these name records in a name database, which each peer on the network has a copy of. With this, users can look up the information for a name without having to search the underlying Bitcoin blockchain.
The Peer Network #
Blockstack uses a peer network called Atlas for users to discover routing information on the network. Atlas enables Blockstack to separate the task of discovering where data is stored from the actual storage of data, allowing for multiple storage providers to coexist.
Each peer stores a table of zone records. A zone record contains a zone file and its hash. For each name record on the virtual chain, there is a corresponding zone record in the local database.

Figure 4: Peer Network.
Any new peers joining the network will communicate with existing ones to get up-to-date information about the zone records.
Storage #
The final layer is the storage layer called Gaia, which enables users to interact with existing cloud storage providers like Dropbox, Google Drive, and Amazon S3. When a user creates an identity on the blockchain, Blockstack associates that identity with a corresponding data store in Gaia.

Figure 5: Storage
Gaia stores data as a key-value store and users can choose what storage providers they want to use. It provides a uniform API for applications to access user data regardless of the storage provider they use.
Before a user writes to their store in Gaia, they encrypt and sign the data with their cryptographic keys. Thus, even though data is stored with existing cloud storage providers, they have no visibility into the data.
Putting them all together #
Quoting the paper, if a Blockstack application wants to look up data for a name, it works as follows:
- Lookup the name in the virtualchain to get the (name, hash) pair.
- Lookup the hash(name) in the Atlas network to get the respective zone file (all peers in the Atlas network have the full replica of all zone files).
- Get the storage backend URI from the zone file and lookup the URI to connect to the storage backend.
- Read the data (decrypt it if needed and if you have the access rights) and verify the respective signature or hash
Conclusion #
Blockstack is a system in use today, and you can learn about some decentralized apps that have been built here. I've also left out some details about Blockstack in this post, and I recommend reading the sites linked in the next section to learn more about its implementation. This post is mainly an exploration of how the internet could be different and perhaps better, using Blockstack as an example.
But blockchain-based apps are not the only approach to building decentralized applications. CRDTs are another approach being actively explored today, and you can find a great overview here.
Overall, I'm intrigued by the decentralization vision for building applications and while it's still some way off being fully realized, the ongoing research is promising.
Further Reading #
- Lecture 20: Blockstack - MIT 6.824 Lecture Notes.
- Blockstack FAQ - Additional material from 6.824.
- Blockstack: A New Internet for Decentralized Applications - Blockstack Technical Whitepaper.
- How Blockstack works - Official Blockstack documentation.
- The Decentralized Internet Is Here, With Some Glitches - Wired article on Blockstack by Tom Simonite.
- Breaking Down Blockstack - Whitepaper Review by Nick Neuman.
- Local-first software by Ink & Switch.
- Maybe we shouldn't want a fully decentralized web by Alessandro Segala.