MIT 6.824: Lecture 16 - Scaling Memcache at Facebook
· 10 min readThis lecture is about building systems at scale. The associated 2013 paper from Facebook doesn't present any new ideas per se, but I found it interesting to see how some ideas this course has covered so far on replication, partitioning and consistency play out in such a large scale system.
The paper is about how Facebook uses memcached as a building block for a distributed key-value store. Memcached is an in-memory data store used for caching. Many applications today benefit from its quick response times and simple API.
In this post, I'll describe how a website's architecture might evolve to cope with increasing load, before describing Facebook's use of memcached to support the world's largest social network.
Table of Contents
- Memcached at Facebook
- Conclusion
- Further Reading
Evolution of web architectures #
Say you're building a website for users to upload pictures to. At the start, you might have your application code, web server, and database running on the same as shown below.
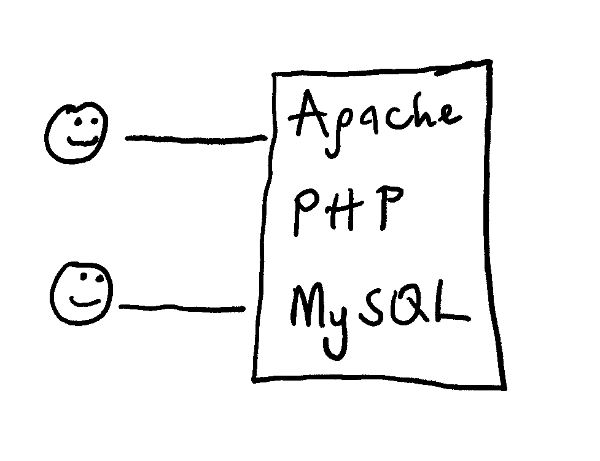
Figure 1 - Evolution of a web architecture: simple, single machine running the application code, web server, and database server.
But as you get more users, the load on your server increases and the application code will likely take too much of the CPU time. Your solution might be to get more CPU power for your application by running a bunch of frontend servers, which will host the web server and the application code while connecting to a single database server as in Figure 2. Connecting to a single database server gives you the advantage of being certain that all your users will see the same data, even though their requests are served by different frontend servers.
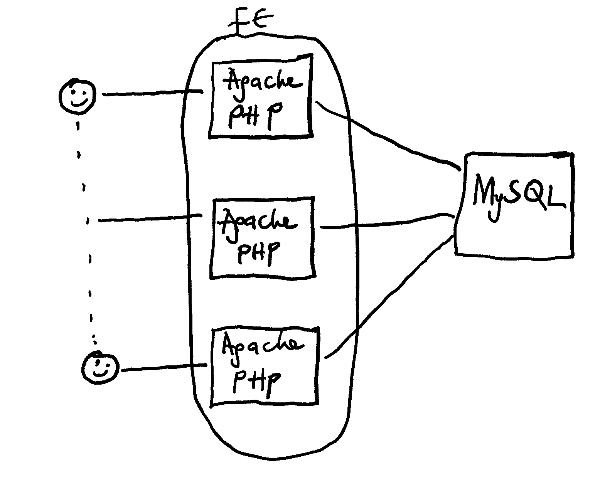
Figure 2 - Evolution of a web architecture: multiple frontend servers to one database server.
As your application grows, the single database server might become overloaded as it can receive requests from an unlimited number of frontend servers. You may address this by adding multiple database servers and sharding your data over those servers as shown in Figure 3. This comes with its challenges—especially around sharding the data efficiently, managing the membership of the different database servers, and running distributed transactions—but it could work as a solution to the problem.
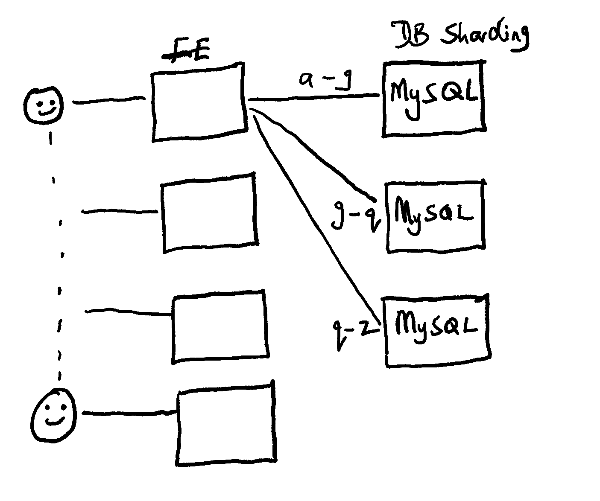
Figure 3 - Evolution of a web architecture: multiple frontend servers to multiple database servers.
But databases are slow. Reading data from disk can be up to 80x slower than reading data stored in memory. As your application's user base skyrockets, one way to reduce this latency in database requests is by adding a cache between your frontend servers and the database servers. With this setup, read requests will first go to the cache and only redirect to the database layer when there's a cache miss.
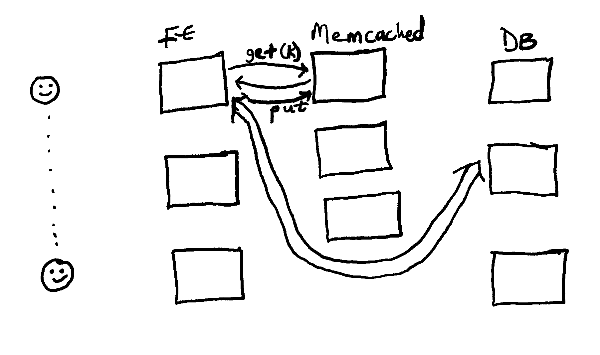
Figure 4 - Evolution of a web architecture: inserting a cache between the frontend and the database.
Maintaining a cache is hard, though. You must keep the cache in sync with the database and work out how to prevent cache misses from overloading the database servers.
This architecture in Figure 4 is similar to Facebook's setup, and the rest of this post will be on Facebook's memcache architecture and how they maintain a cache effectively.
Memcached at Facebook #
Facebook uses memcached to reduce the read load on their databases. Facebook's workload is dominated by reads and memcached prevents them from hitting the database for every request. They use memcached as a look-aside cache. This means that when a web server needs data, it first attempts to fetch the data from the cache. If the value is not in the cache, the web server will fetch the data from the database and then populate the cache with the data.
For writes, the web server will send the new value for a key to the database and then send another request to the cache to delete the key. Subsequent reads for the key will fetch the latest data from the database.
This is illustrated below.
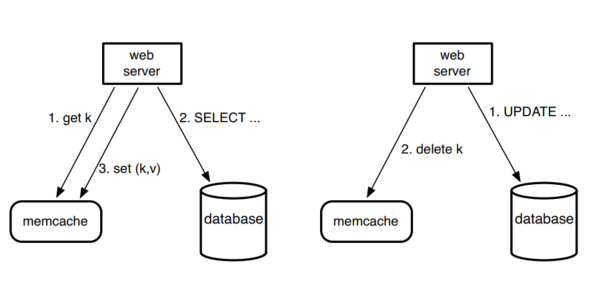
Figure 5 - Memcache as a demand-filled look-aside cache. The left half illustrates the read path for a web server on a cache miss. The right half illustrates the write path.
Note that the paper uses memcached to refer to the open source library and memcache to refer to the distributed system built on top of memcached at Facebook. I'll use memcache for the rest of this post.
Architecture #
Facebook's architecture comprises multiple web, memcache, and database servers. A collection of web and memcache servers make up a frontend cluster, and multiple frontend clusters make up a data centre. These data centres are called regions in the paper. The frontend clusters in a region share the same storage cluster. Facebook replicates clusters in different regions around the world, designating one region as the primary and the others as secondary regions.
The architecture diagram below illustrates these components:
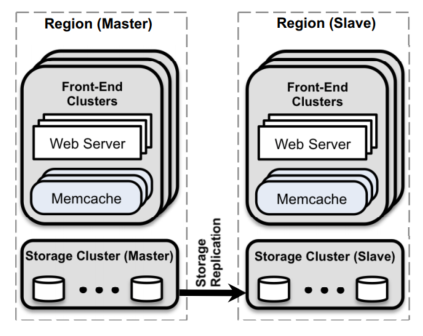
Figure 6 - Overall architecture
Each layer in this architecture comes with its set of challenges, and I'll cover those next.
In a cluster: Latency and Load #
For performance in a cluster, the designers of this system focused on two things:
- Reducing the latency of memcache's response.
- Reducing the load on the database when there's a cache miss.
Reducing latency #
Facebook's efforts to reduce latency in a cluster focused on optimising the memcache client. The memcache client runs on each web server and interacts with the memcache servers in its frontend cluster. This client is responsible for request routing, request batching, error handling, serialization, and so on. Next, let's see some optimizations made in the client.
Memcache clients parallelise and batch requests #
Each web server constructs a directed acyclic graph (DAG) of all the data dependencies it needs for a page. The memcache client then uses this DAG to batch and fetch the required keys concurrently from the memcache servers. This reduces the number of network round trips needed to load a Facebook page.
UDP for reads and TCP for writes #
Memcache clients use UDP for get requests and TCP for set and delete requests to the servers. I've written about the differences between UDP and TCP in an earlier post, but what's relevant here is that using UDP reduces the latency and overhead compared to TCP, which makes it less reliable for transmission.
When the UDP implementation detects that packets are dropped or received out of order (using sequence numbers), it returns an error to the client which treats the operation as a cache miss. But unlike a standard cache miss (i.e. one not related to dropped packets) which will redirect to the database and then populate the cache, the web server will not attempt to populate the cache with the fetched data. This avoids putting extra load on a potentially overloaded network or server.
Memcache clients implement flow control #
Facebook partitions data across hundreds of memcache servers in a cluster using consistent hashing. Thus, a web server may need to communicate with many memcache servers to satisfy a user's request for a page. This leads to the problem of incast congestion. The paper describes this problem:
When a client requests a large number of keys, the responses can overwhelm components such as rack and cluster switches if those responses arrive all at once.
Memcache clients address this by using a sliding window mechanism similar to TCP's to limit the number of outstanding requests. A client can make a limited number of requests at a time and will send the next one only when it has received a response from an in-flight one.
Reducing load #
As I wrote earlier, Facebook uses memcache to reduce the read load on their databases. But when data is missing from the cache, the web servers must send requests to these databases. Facebook had to take extra care when designing the system to prevent the databases from getting overloaded when there are many cache misses. They use a mechanism called leases to address two key problems: stale sets and thundering herds.
Leases and stale sets #
A stale set occurs when a web server sets an out-of-date value for a key in memcache. This can happen when concurrent updates to a key get reordered. For example, let's consider this scenario to illustrate a stale set with two clients, C1 and C2.
key 'k' not in cache
C1 get(k), misses
C1 reads v1 from DB as the value of k
C2 writes k = v2 in DB
C2 delete(k) (recall that any DB writes will invalidate key in cache)
C1 set(k, v1)
now mc has stale data, since delete(k) has already happened
will stay stale indefinitely until k is next written
Leases prevent this problem. When a client encounters a cache miss for a key, the memcache server will give it a lease to set data into the cache after reading it from the DB. This lease is a 64-bit token bound to the key. When the client wants to set the data in the cache, it must provide this lease token for memcache to verify. But, when memcache receives a delete request for the key, it will invalidate any existing lease tokens for that key.
Therefore, in the above scenario, C1 will get a lease from mc which C2's delete() will invalidate. This will lead to memcache ignoring C1's set. Note that this key will be missing from the cache and the next reader has to fetch the latest data from the DB.
Leases and thundering herds #
A thundering herd happens when many clients try to read the data for an invalidated key. When this happens, the clients will all have to send their requests to the database servers, which may get overloaded.
To prevent the thundering herd problem, memcache servers give leases only once every 10 seconds per key. If another client request for a key comes in within 10 seconds of the lease being issued, the request will have to wait. The idea is that the first client with a lease would have successfully set the data in the cache during the 10 seconds window, and so the waiting clients will read from the cache on retry.
In a region: Replication #
As Facebook's load increased, they could have scaled their system by adding more memcache and web servers to a frontend cluster and further partitioning the keyset. However, this has two major limitations:
- Incast congestion will get worse as the number of memcache servers increases, since a client has to talk to more servers.
- Partitioning by itself does not help much if a key is very popular, as a single server will need to handle all the requests for that key. In cases like this, replicating the data helps so we can share the load among different servers.
Facebook scaled this system by creating multiple replicas of a cluster within a region which share common storage. These clusters are called frontend clusters, with each cluster made up of web and memcache servers. This method addresses both limitations described above and provides an extra benefit: having smaller clusters instead of a single large one gives them more independent failure domains. They can lose a frontend cluster and still continue operating normally.
What's interesting to me here is that there is no special replication protocol to ensure that the clusters in a region have the same data. Their thinking here is that if they randomly route users' requests to any available frontend cluster, they'll all eventually have the same data.
Let's now see some optimizations made within a region.
Regional Invalidation #
To keep memcache content in the different frontend clusters consistent with the database, the storage cluster sends invalidations to the memcache servers after a write from a web server. As an optimization, when a web server changes data in the storage cluster, it must also send the invalidations to the memcache servers in its local frontend cluster.
The paper points out that this guarantees read-after-write consistency for a single user request. My understanding here is that they randomly route each user's request to a frontend cluster in a region, but that routing is consistent across all the user's subsequent requests.
The storage cluster batches the changes and sends them to a set of dedicated servers in each frontend cluster. These dedicated servers then unpack the changes and route the invalidations to the right memcache servers. This mechanism results in fewer packets than if the storage cluster was sending each invalidation for a key directly to the memcache server holding that key.
Regional Pools #
Items in a dataset which are accessed infrequently and have large sizes rarely need to be replicated. For those keys, there is an optimization in place to store only one copy per region.
Facebook stores these keys in a regional pool, which contains a set of memcache servers that are shared by multiple frontend clusters. This is more memory efficient than over-replicating items with a low access rate.
Cold Cluster Warmup #
When a new frontend cluster is being brought online, any requests to it will result in a cache miss, and this could lead to overloading the database. Facebook has a mechanism called Cold Cluster Warmup to mitigate this.
Quoting the paper to describe the solution:
Cold Cluster Warmup mitigates this by allowing clients in the “cold cluster” (i.e. the frontend cluster that has an empty cache) to retrieve data from the “warm cluster” (i.e. a cluster that has caches with normal hit rates) rather than the persistent storage.
Across Regions: Consistency #
Facebook deploys regions across geographic locations worldwide. This has a few advantages:
- Web servers can be closer to users, which reduces the latency in responding to requests.
- Better fault tolerance since we can withstand natural disasters or power failures in one region.
- New locations can provide cheaper power and other economic benefits.
Facebook designates one region to hold the primary database which all writes must go to, and the other regions to contain read-only replicas. They use MySQL's replication mechanism to keep the replica databases in sync with the primary. The key challenge here is in keeping the data in memcache consistent with the primary database, which may be in another region.
With the information stored on Facebook—friend lists, status, posts, likes, photos—it is not critical for users to always see fresh data. Users will typically tolerate seeing slightly stale data for these things. Thus, Facebook's setup allows for users in a secondary region to see slightly stale data for the sake of better performance. The goal here, though, is to reduce that window of staleness and ensure that the data across all regions is eventually consistent.
There are two major considerations here:
- When writes come from a primary region.
- When writes come from a secondary region.
Writes from a primary region #
This follows the mechanism described earlier. Writes go directly to the storage cluster in the region, which then replicates it to the secondary regions. Clients in secondary regions may read stale data for any key modified here if there is a lag in replicating the changes to those regions.
Writes from a secondary region #
Consider the following race that can happen when a client C1 updates the database from a secondary region:
Key k starts with value v1
C1 is in a secondary region
C1 updates k=v2 in primary DB
C1 delete(k) (in local region)
C1 get(k), miss
C1 reads local DB -- sees v1, not v2!
later, v2 arrives from primary DB (replication lag)
This violates the read-after-write consistency guarantee, and Facebook prevents this scenario by using remote markers. With this mechanism, when a web server in a secondary region wants to update data that affects a key k, it must:
- Set a remote marker rk in the regional pool. Think of rk as a memcache record that represents extra information for key k.
- Send the write to the primary region and include rk in the request, so that the primary knows to invalidate rk when it replicates the write.
- Delete k in the local cluster.
By doing this, the web server's next request for k will result in a cache miss, after which it will check the regional pool to find rk. If rk exists, it means the data in the local region is stale and the server will direct the read to the primary region. Otherwise, it will read from the local region.
Here, Facebook trades additional latency when there's a cache miss for a lower probability of reading stale data.
Conclusion #
I've often thought of using caches primarily to reduce the latency in a system, but this lecture has been an eye-opener in also thinking of caches as being vital for throughput survival. I've left out some bits from the paper on fault tolerance and single server improvements, which I'll encourage you to read up on. Also, the paper doesn't say much about this, but I'll be interested in learning more about what pages are cached on Facebook.
I suspect that this paper is severely outdated and a recent paper from Facebook makes me believe that memcache is no longer used there (this is subject to confirmation, though), but the ideas in here are still very relevant.
Further Reading #
- Scaling Memcache at Facebook - Original paper from Facebook.
- Scaling Memcache at Facebook - MIT 6.824 lecture notes.
- Scaling memcached at Facebook - Post on Facebook's engineering blog.