MIT 6.824: Lecture 9 - CRAQ
· 6 min readMany distributed systems today sacrifice stronger consistency guarantees for the sake of greater availability and higher throughput. CRAQ, which stands for Chain Replication with Apportioned Queries, is a system designed to challenge this tradeoff. CRAQ's approach differs from existing replication techniques we have seen so far, like in Raft. It improves on the original form of Chain Replication.
CRAQ is a distributed object-storage system that maintains strong consistency while still providing a high read throughput. Object-storage systems are better suited for applications that need flat namespaces, such as a key-value store. These are unlike file-based systems, which store data in a hierarchical directory structure.
This post will start by describing Chain Replication, before presenting how CRAQ improves on it.
Table of Contents
Chain Replication #
Chain Replication is an approach to replicating data across multiple nodes that involves arranging the nodes in a chain of a defined length C. All the write operations from clients go to the head of the chain, which passes them down to the next node in the chain. When a node receives a write operation, it applies the write and passes it down to the next node in the chain until the write reaches the tail node.
The tail node handles all read operations. This is because a write will not reach the tail until all the other replicas in the chain have applied it. The write is marked as committed when it reaches the tail. Therefore, a read will only return committed values.
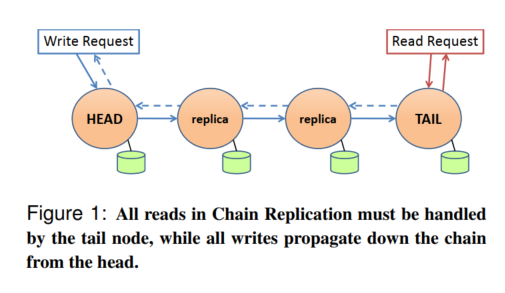
Figure 1 illustrates a sample chain of length four. As shown by the dashed lines in the figure, the tail sends an acknowledgment back to the head when it commits a write.
Chain replication achieves strong consistency #
Since all reads go to the tail and the tail stores all the committed write operations, the tail can apply a total ordering over all the operations. There is no possibility of a client seeing stale data. Concurrent reads to the tail will always return the most up-to-date value.
Write operations are cheaper #
Another advantage of chain replication is that the cost of writes is spread equally over all nodes. Unlike in primary/backup replication where the primary node transmits data to all its backups, each node in chain replication transmits only to its successor in the chain. The simulation results by the paper's authors showed that chain replication achieved competitive or superior write throughput when compared with primary/backup replication.
The tail is a bottleneck #
The major downside of chain replication is that since all the reads must go to the tail, read throughput cannot scale linearly with chain size. This is a trade-off that this approach makes to guarantee strong consistency. If clients can read from intermediate nodes, there is a possibility of concurrent reads for the same value to different nodes seeing different writes as they are being passed down the chain.
CRAQ, which we will discuss next, helps to address this downside.
CRAQ #
CRAQ (Chain Replication with Apportioned Queries) is a modification of chain replication that increases the read throughput by allowing any node in the chain to handle read requests, while still guaranteeing strong consistency. CRAQ works as follows:
-
Each node in the chain can store multiple versions of an object: one clean version and a dirty version per recent write.
-
For write operations:
-
Clients send writes to the head.
-
As the write passes through a replica, the replica creates a new dirty version for that object.
-
The tail creates a clean version for the object when it receives the write and sends an acknowledgment back along the chain.
-
When a node receives an acknowledgment for an object version, it marks the latest object version as clean and deletes all previous versions for the object.
-
-
For reads from non-tail nodes:
- If the latest version that a node has for an object is clean, it replies with that version.
- Otherwise, it will ask the tail for the last committed version number for that object and returns that version of the object (also known as a version query).
If a node returns the most recent clean version of an object without asking the tail first, it may violate strong consistency, as the tail may have exposed a newer clean version to another reader.
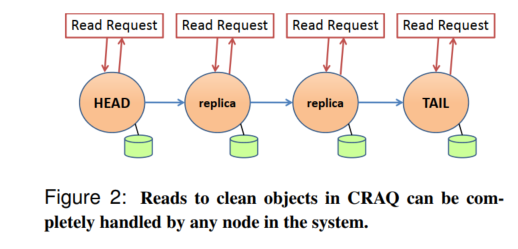
In Figure 2, we see a CRAQ chain in the starting clean state. All the nodes will return the same value for any read request since they store an identical copy of the object. The nodes will remain in a clean state until they receive a write operation.
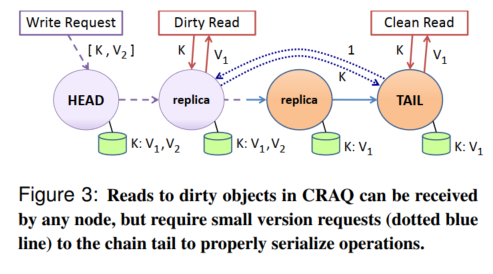
Figure 3 illustrates a dirty read situation where the successor node to the head makes a version query to the tail for its latest version number. The write request received at the head is still in propagation when the dirty read for key K comes in, which is why the node has multiple versions of the object.
The node then makes a version query to the tail node which returns V1 since that it's latest committed value. As a result, the dirty node returns the object value associated with the version number it gets from the tail. If a clean replica had received the read request, it would have returned its value immediately with no version query.
CRAQ offers throughput improvements over the standard chain replication in two different scenarios:
- Read-Mostly Workloads: Here, most of the reads to the C-1 non-tail nodes will be clean reads, and so the throughput can scale linearly with the chain size C.
- Write-Heavy Workloads: These have most read requests to non-tail nodes as dirty, and require version queries to the tail. However, these version queries are more light-weight than reading full objects from the tail, which allows the tail to process them at a higher rate.
The performance evaluation of CRAQ described in the paper showed that its read throughput is higher than in chain replication under these workloads.
Consistency models on CRAQ #
CRAQ supports the varying needs of applications by providing three consistency models:
- Strong Consistency: This works as described above. The guarantee is that all object reads will return the last committed write.
- Eventual Consistency: For applications that may not need always need the latest version of an object, this allows an intermediate node to return the newest object version it knows about without contacting the tail. This means that a subsequent read to a different node for the same object may return an object version that is older than the previous one returned.
- Eventual Consistency with Maximum-Bounded Inconsistency: This allows read requests to a node to return the newest object version it is aware of, but only to a certain point. We can set a limit based on either the time (relative to the local clock of a node) or an absolute version number. The advantage over the standard eventual consistency is that it guarantees that the value of a read operation has a maximum inconsistency period.
CRAQ needs a configuration manager #
Unlike Raft, the CRAQ protocol cannot prevent a split-brain by itself. It is only concerned with data replication and does not handle things like leader (or head) election in the event of partitions. To address this, CRAQ is usually coupled with a configuration manager like ZooKeeper to deal with managing the nodes that make up a chain and handling leader election for the chain.
To recover from failure, each node in a chain keeps track of its predecessor and successor, as well as the chain head and tail. When a head fails, its immediate successor becomes the new head. Similarly, the tail's immediate predecessor takes over when the tail fails. Intermediate nodes can also be replaced by adding a new node between two nodes like in a doubly-linked list.
The configuration manager manages the nodes that make up a chain and choosing the chain's head and tail.
One slow node can weaken the chain #
The major downside to CRAQ (and the standard chain replication) is that it requires all the nodes in the chain to take part before any write can commit. This is unlike quorum systems like Raft and ZooKeeper that only need a majority of the nodes to participate.
The upshot of this is that CRAQ by itself is less fault-tolerant than Raft and ZooKeeper as the system's throughput can be severely affected by at least one slow node.
Conclusion #
CRAQ is a straightforward approach to replication with minimal chit-chat compared to a system like Raft, with its downside being that it's not very fault-tolerant as it needs all the nodes in a chain to respond to writes. It will be interesting to explore a quorum-based approach to chain replication.
Further Reading #
- Object Storage on CRAQ - Original paper by Jeff Terrace and Michael J. Freedman.
- Lecture 9: Chain Replication, CRAQ - MIT 6.824 lecture notes.