MIT 6.824: Lecture 8 - ZooKeeper
· 8 min readThis week's lecture was on ZooKeeper, with the original paper being used as a case study. The paper sheds light on the following questions:
- Can the coordination of distributed systems be handled by a stand-alone general-purpose service? If so, what should the API of that service look like?
- Can we improve the performance of a system by N times if we add N times replica servers? That is, can the performance scale linearly by adding more servers?
This post will start by addressing the second question and discussing how ZooKeeper's performance can scale linearly through the guarantees it provides. In a later section, we'll discuss how ZooKeeper's API allows it to act as a stand-alone coordination service for distributed systems.
Table of Contents
- ZooKeeper
- Conclusion
- Further Reading
ZooKeeper #
Overview #
ZooKeeper is a service for coordinating the processes of distributed applications. Coordination can be in the form of:
- Group membership: Ensuring that members of a group know about all the other members of that group. The set of replicas involved in a Raft log entry replication form a group, for example.
- Configuration: Keeping track of the operational parameters needed by the nodes in a cluster. Configuration items could include database server URLs for different environments, security settings, etc.
- Leader Election: Like Raft, ZooKeeper can also be used to coordinate the election of a leader among a set of nodes.
ZooKeeper can scale linearly #
Let's consider the distributed key-value store shown below which makes use of a Raft module in each replica. As discussed in the previous lecture, all the writes in Raft must go through a leader. To guarantee a linearizable history, all reads must go through the leader as well. One reason why reads cannot be sent to followers is that a replica may not be in the majority needed by Raft, and so may return stale value which violates linearizability.
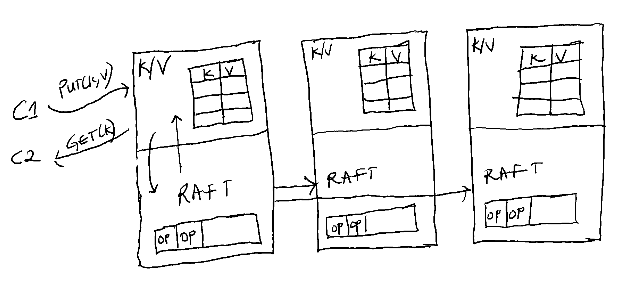
Figure 1 - Sample Key-Value store using Raft for replication.
Going back to the second question asked at the beginning of this post:
If we added 2x more replicas to this setup, is there a chance that we could get 2x better performance of reads and writes?
The simple answer is: it depends. In a Raft based system like in Figure 1, adding more servers will likely degrade the performance of the system. This is because all the reads must still go through the leader, and the leader now has to store more information about the new servers.
ZooKeeper, on the other hand, allows us to scale the performance of our system linearly by adding more servers. It does this by relaxing the definition of correctness and providing weaker guarantees for clients. Reads can be served from any replica but writes are still sent to a leader. While this has the downside that reads may return stale data, it greatly improves the performance of reads in the system. ZooKeeper is a system designed for read-heavy workloads, and so the trade-off that leads to better read performance is worth it.
Next, we'll discuss the two basic ordering guarantees provided by ZooKeeper that make it suitable as a distributed coordination system.
Writes to ZooKeeper are linearizable #
ZooKeeper guarantees linearizable writes, stated in the paper as:
All requests that update the state of ZooKeeper are serializable and respect precedence.
This means that if Client A writes a value for key X, any subsequent updates to that key by another client will first see the write by Client A. The leader chooses an order for the writes, and that order is maintained on all the followers.
Note that the distinction between this and linearizable reads is that the lack of linearizable reads here means that clients can read stale values for a key. For example, if a value for key X is updated by client A on one server, a read on another server for that key by client B may return the old value. This is because the freshness guarantee for ZooKeeper only applies to writes.
Client Requests are FIFO #
A client is any user of the ZooKeeper service. The guarantee for clients is stated as:
All requests from a given client are executed in the order that they were sent by the client.
In other words, each client can specify an order for its operations (reads and writes), and that order will be maintained by ZooKeeper when executing.
These guarantees combined can be used to implement many useful distributed system primitives despite the weaker consistency guarantee. Note that ZooKeeper does provide optional support for linearizable reads which comes with a performance cost.
ZooKeeper as a service #
ZooKeeper is a good example of how the coordination of distributed systems can be handled by a stand-alone service. It does this by exposing an API that application developers can use to implement specific primitives. Some examples of this are shown in a later section.
The ZooKeeper service is made up of a cluster of nodes that use replication for better fault tolerance and performance. Clients communicate with ZooKeeper through a client API contained in the client library. The client library also handles the network connections between ZooKeeper servers and the client. Some systems covered in the previous lectures where ZooKeeper could be used are:
- VMware FT's Test-and-Set server: The system uses a test-and-set server to prevent split-brain by ensuring that the operation can succeed for only one of the replicas in the event of a network partition. This test-and-set server needs to be fault-tolerant. ZooKeeper is a fault tolerant service that allows to implement primitives like test-and-set operations.
- GFS: GFS (pre-Colossus) made use of a single master to keep track of the metadata related to the chunks in the system. ZooKeeper could have played this role in the system and maybe even improved performance since all the replicas of the master would have been able to serve reads.
- In MapReduce, ZooKeeper can be used to keep track of information like who the current master is, the list of workers, what jobs are assigned to what workers, the status of tasks, etc.
ZooKeeper uses a leader-based atomic broadcast protocol called Zab to guarantee that writes are linearizable in the system. You can think of Zab as a consensus protocol similar to Raft or Paxos.
Data Model #
ZooKeeper provides a client API to manipulate a set of wait-free data objects known as znodes. Znodes are organized in a hierarchical form similar to file systems, and we can refer to a given znode using the standard UNIX notation for file systems. For example, we can use /A/B/C to refer to znode C which has znode B as its parent, where B has znode A as its parent.
A client can create two types of znodes:
- Regular: Regular znodes are created and deleted explicitly.
- Ephemeral: Ephemeral znodes can either be deleted explicitly or are automatically removed by the system when the session that created them is terminated.
In addition, a client can set a sequential flag when creating a new znode. When this flag is set, the znode's name is appended with the value of a monotonically increasing counter. For example, If z is the new znode and p is the parent znode's name, then the sequence value of z will be greater than that of any other sequential child znode of p created before z.
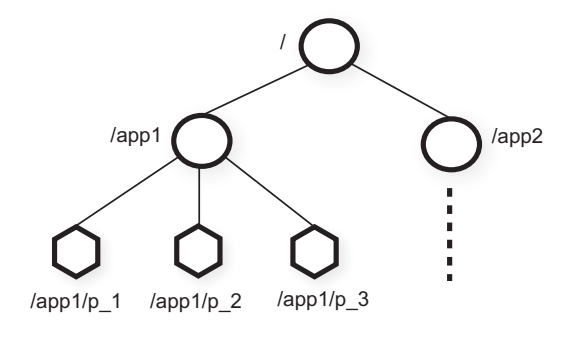
Figure 2: Illustration of ZooKeeper's hierarchical name space.
Znodes map to client abstractions #
Znodes of either type can store data but only regular znodes can have children. Znodes are not designed for general data storage but are instead to use represent abstractions in a client's application. For example, the figure above has two subtrees for Application 1 and Application 2. Application 1 also has a subtree that implements a group membership protocol. The client processes p1-pn each create a znode pi under /app1. In this example, the znodes are used to represent the processes for an application, and a process can be aware of its group members by reading from the /app1 subtree.
Znodes can also store specific metadata #
Note that although znodes are not designed for general data storage, they allow clients to store specific metadata or configuration. For example, it is useful for a new server in a leader-based system to learn about which other server is the current leader. To achieve this, the current leader can be configured to write this information in a known znode space. Any new servers can then read from that znode space.
There is also some metadata associated with znodes by default like timestamps and version counters, with which clients can execute conditional updates based on the version of the znode. This will be explained further in the next section.
Client API #
The ZooKeeper client API exposes a number of methods. Here are a few of them:
create(path, data, flags): Creates a znode with pathname path, stores data[] in it, and
returns the name of the new znode. flags enables a client to select the type of znode: regular, ephemeral, and set the sequential flag;
delete(path, version): Deletes the znode path if that znode is at the expected version;
exists(path, watch): Returns true if the znode with path name path exists, and returns false otherwise. The watch flag enables a client to set a watch on the znode;
getData(path, watch): Returns the data and meta-data, such as version information, associated with the znode. The watch flag works in the same way as it does for exists(), except that ZooKeeper does not set the watch if the znode does not exist;
setData(path, data, version): Writes data[] to znode path if the version number is
the current version of the znode;
getChildren(path, watch): Returns the set of names of the children of a znode;
sync(path): Waits for all updates pending at the start of the operation to propagate to the server that the client is connected to.
Note the following about the client API:
- When clients connect to ZooKeeper, they establish a session. It is through this session that ZooKeeper can identify clients in fulfilling the FIFO order guarantee.
- The sync method can be used to ensure that the read for a znode is linearizable, though it comes at a performance cost. It forces a server to apply all its pending write requests before processing a read.
- All the methods have both a synchronous and asynchronous version available through the API.
- The update methods(delete and setData) take an expected version number. If this differs from the actual version number of the znode, the operation will fail.
- When the watch parameter in the read methods (getData and getChildren) is set, the operation will complete as normal except that the server promises that it will notify the client when the returned information changes. This is another optimization made in ZooKeeper to prevent a client from continuously having to poll for the latest information.
Implementing primitives using ZooKeeper #
Using ZooKeeper for Configuration Management #
To implement dynamic configuration management with ZooKeeper, we can store configuration in a znode, zc. When a process is started, it starts up with the full pathname of zc. The process can get its required configuration by reading zc and setting the watch flag to true. It will get notified whenever the configuration changes, and can then read the new configuration with the watch flag set to true again.
Using ZooKeeper for Rendezvous #
Let's consider a scenario where a client wants to start a master process and many worker processes, with the job of starting the processes being handled by a scheduler. The worker processes will need information about the address and port of the master to connect to it. However, because a scheduler starts the processes, the client will not know the master's port and address ahead of time for it to give to the workers.
This can be handled by the client creating a rendezvous znode, zr, and passing the full pathname of zr as a startup parameter to both the master and worker processes. When the master starts up, it can fill in zr with information about its address and port. The workers can read from the znode when they start up and set the watch flag set to true. This way, workers will get notified when zr is updated and can use the information there.
Using ZooKeeper for Group Membership #
As described in an earlier section, we can use ZooKeeper to implement group membership by creating a znode zg to represent the group. Any process member of the group can create an ephemeral child znode with a unique name under zg. The znode representing a process will be automatically removed when the process fails or ends.
A process can obtain other information about the other members of its group by listing the children under zg. It can then monitor changes in group membership by setting the watch flag to true.
Conclusion #
The design of ZooKeeper is another great example of tailoring a system for a specific use case; in this example, strong consistency was relaxed to improve the performance of reads in read-mostly workloads. The results in the paper show that the throughput of ZooKeeper can scale linearly. ZooKeeper is also used in many distributed systems today, and you can find a list of some of those here.
There are a few more details about the implementation of ZooKeeper that were skipped in this post which you can find in the paper about things like how replication works, the atomic broadcast protocol, request handling from clients, etc. The section below contains links that can help if you're interested in learning more about these details.
Further Reading #
- ZooKeeper: Wait-free coordination for Internet-scale systems - Original paper.
- ZooKeeper recipes - Further examples of how ZooKeeper can be used.
- Managing configuration of a distributed system with Apache ZooKeeper by Oleg Yermolaiev.
- KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum - Interesting discussion on the plan to replace ZooKeeper with Raft in Apache Kafka.
- Linearizability - Jepsen post on Linearizability.