MIT 6.824: Lecture 4 - Primary/Backup Replication
· 10 min readThis lecture's material was on the subject of replication as a means of achieving fault tolerance in a distributed system. The VMware FT paper was used as a case study on how replication can be implemented.
- VMware FT Paper Summary
Replication Approaches #
There are two main ways in which replication can be implemented in a cluster:
- State Transfer: In this mode, the primary replica executes all the relevant operations and regularly ships its state to the backup(s). This state could include CPU changes, memory and I/O device changes, etc, and this approach to replication often requires a lot of bandwidth.
- Replicated State Machine: The idea here is that if two state machines are fed the same input operations in the same order, their outputs will be the same. The caveat is that these input operations should be deterministic. VMware FT uses this approach for replication and does work to ensure that non-deterministic operations are applied in a deterministic way. This will be explained further in a later section.
Replication Challenges #
Implementing replication is challenging, and some of those challenges deal with answering the questions:
- What state do we replicate?
- Should the primary machine always wait for the backup to apply the replicated state?
- When should the backup should take over and become the primary?
- How do we ensure that a replacement backup gets in sync with the primary?
As for what state to replicate, the options include:
- Application-Level State: An example of this is replicating a database's tables. GFS replicates application-level state. In this case, the primary will only send high level operations like database queries to its backups.
- Machine-Level State: This involves replicating things like the contents of the RAM and registers, machine events like interrupts and DMA, etc. The primary also forwards machine events (interrupts, DMA) to the backup. VMware FT replicates machine-level state. It's able to do this because it has full control of the execution of both the primary and backup, which makes it easier to deal with non-deterministic events. I'll go into more detail about this later.
For all the benefits of replication, it's important to note that replication is not able to protect against all kinds of failures. There are different failure modes in distributed systems and the failures dealt with in the paper's implementation are fail-stop failures.
Fail-stop failures are noticeable failures which cause a machine to stop executing. Here, it is assumed that the machine will not compute any bad results in the process of failing. Replication can help to provide fault tolerance for these kinds of failures. On the other hand, replication may less helpful when dealing with hardware defects, software bugs or human configuration errors. These may sometimes be detected using checksums, for example.
VMware FT Paper Summary #
Glossary #
- Guest OS: A Guest OS is the operating system installed on a virtual machine.
- Hypervisor: A Hypervisor (also known as a Virtual Machine Monitor) is the software which creates, runs and manages virtual machines.
- Host OS: The Host OS is the operating system installed on the physical machine on which the hypervisor runs. (Note: There are some hypervisors which interact directly with the hardware in place of a Host OS, but those are not the focus of this topic.)
- Virtual Machine: A virtual machine is an emulation of a physical computer system. Like physical machines, virtual machines are able to run an operating system and execute its applications as normal.
- VMware vSphere FT: This is an implementation of fault tolerance on VMware's cloud computing virtualization platform.
Overview #
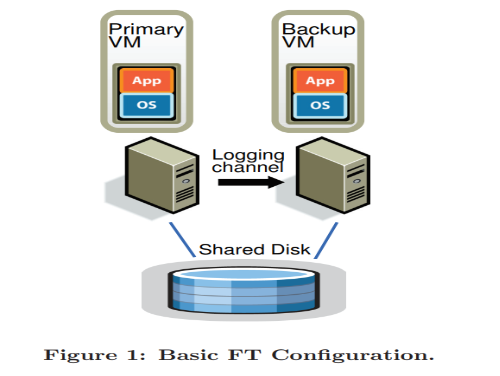
Figure 1 illustrates the FT configuration which involves a primary VM and its backup VM. The backup VM is located on a different physical server from the primary and is kept in sync with the execution of the primary. The VMs are said to be in virtual lock-step. They also have their virtual disks located on shared storage, which means that the disks are accessible by either VM.
All the inputs (e.g. network, mouse, keyboard, etc.) go to the primary VM. These inputs are then forwarded to the backup VM via a network connection known as the logging channel. For non-deterministic input operations, additional information is also sent to ensure that the backup VM executes them in a deterministic way. Both VMs execute these operations but only the outputs produced by the primary VM are visible to the client. The outputs of the backup VM get dropped by the hypervisor.
Deterministic Replay #
As mentioned earlier, for state machine replication to work, there needs to be a way to deal with the presence of non-deterministic instructions. A virtual machine can have non-deterministic events like virtual interrupts, and non-deterministic operations like reading the current clock cycle counter of the processor. These instructions may yield different results even if the primary and its backup have the same state. Therefore, it is important for them to be handled carefully to ensure consistency between the two machines.
The occurrence of this non-determinism presents three challenges when replicating the execution of a VM:
- All the input and non-determinism on the primary VM must be correctly captured to ensure that it can be executed deterministically on the backup VM.
- The inputs and non-determinism must be correctly applied to the backup VM.
- They must be applied in a manner that does not degrade the performance of the system.
To deal with these challenges, VMware has a deterministic replay functionality that is able to capture all the inputs to a primary VM as well as possible non-determinism, and replay these events in their exact order of execution on a backup VM.
FT Protocol #
We have seen so far that VMware FT uses deterministic replay to produce the relevant log entries and ensure that the backup VM executes identically to the primary VM. However, to ensure that the backup VM consistent in a way that makes it indistinguishable from the primary to a client, VMware FT has the following requirement:
Output Requirement: If the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the primary VM has sent to the external world.
The rule set in place to achieve the output requirement is the Output Rule stated as follows:
Output Rule: The primary VM may not send an output to the external world, until the backup VM has received and acknowledged the log entry associated with the operation producing the output.
The idea is that as long as the backup VM has received all the log entries (including for any output-producing operations), then it will be able to replay up to the state last seen by the client if the primary VM crashes.
This rule is illustrated below.
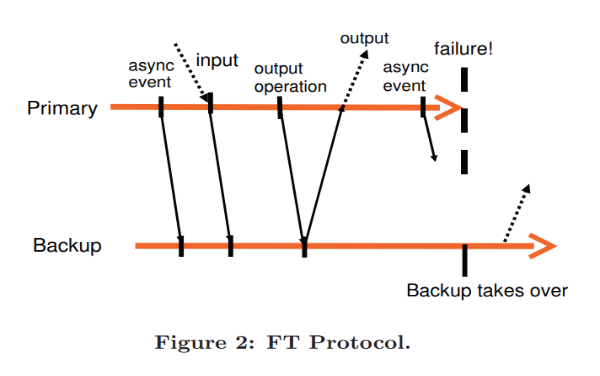
As shown in Figure 2, the output to the external world is delayed until the primary VM has received an acknowledgment from the backup VM that it has received the associated log entry for the output operations.
Note: VMware FT does not guarantee that all outputs are produced exactly once during a failover situation. In a scenario where the primary crashes after the backup has received the log entry for the latest output operation, the backup cannot tell if the primary crashed immediately before or after sending its latest output. Therefore, the backup may re-execute an output operation. The good news is that the VMware setup can rely on its network infrastructure to detect duplicate packets and prevent them from being retransmitted to the client.
Detecting and Handling Failures #
Heartbeat operations are used in combination with monitoring the traffic on the logging channel to detect failures of either VM. The system can rely on the traffic on the logging channel because it logs timer interrupts (which occur regularly on a guest OS), and so when the traffic slows down, it can safely assume that the guest OS is not functioning.
If the backup fails, the primary stops sending entries on the logging channel and just keeps executing as normal. If you're wondering how the backup will be able to catch up later, VMware has a tool called VMotion that is able to clone a VM with minimal interruption to the execution of the VM. I'll touch more on that later.
If the primary fails, the backup VM must first replay its execution until it has consumed the last log entry. After that point, the backup will take over as the primary and can now start producing output to the external world.
To avoid a split-brain situation by ensuring that only one VM can be the primary at a time, VMware uses an atomic test-and-set operation on the shared storage. This is relevant if the primary and backup lose network communication with each other and they both attempt to go-live. The operation will succeed for only one of the machines at a time.
VMware FT is able to restore redundancy when either of the VMs fails by automatically starting a new backup VM on another host.
Practical Implementation of FT #
Starting and Restarting VMs #
A challenge in building a system like this is in figuring out how to start up a backup VM in the same state as the primary VM while the primary is running. To address this, VMware modified an existing tool called VMware VMotion. In its original form, VMware VMotion allows for a running VM to be migrated from one server to another with minimal disruption. However, for fault tolerance purposes, the tool was reworked as FT VMotion to allow for the cloning of a VM to a remote host. This cloning operation interrupts the execution of the primary by less than a second.
A logging channel is set up automatically by FT VMotion between the source VM and the destination, with the source entering logging mode as the primary, and the destination entering replay mode as a backup.
Managing the Logging Channel #
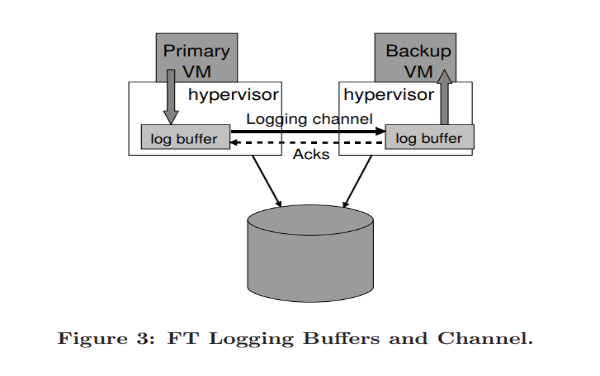
Figure 3 above illustrates how the flow of log entries from when they are produced by the primary VM to their consumption at the backup VM.
If the log buffer of the backup VM is empty, the VM will stop its execution until the next log entry arrives. This pause can be tolerated since the backup VM is not interacting with clients.
On the other hand, the primary VM will stop executing when its log buffer is full, and the execution is paused until the log entries are flushed out. However, this pause can affect clients and so work must be done to minimize the possibility of the log buffer getting filled up.
The log buffer of the primary may fill up when the backup VM is executing too slowly and thus consuming its log entries too slowly. This can happen when the host machine of the backup VM is overloaded with other VMs, and so the backup is unable to get enough CPU and memory resources to execute normally.
Apart from avoiding the pauses due to a full log buffer in the primary VM, another reason why we do not want the backup to execute slowly is to reduce the time that it takes to "go-live"; i.e. during the failover process, if the backup is lagging far behind the latest log entry, it will take longer for the backup to take over as the primary. This delay will be noticeable by a client.
Interestingly, a mechanism has been implemented in VMware FT to slow down the execution of the primary VM when the backup VM is starting to get far behind (more than 1 second behind according to the paper). The execution lag between the primary and backup VM is typically less than 100 milliseconds, and so it makes sense that a lag of 1 second will raise an alarm. The primary VM is slowed down by giving it a smaller amount of CPU resources to use.
Implementation Issues for Disk IO #
This section details some challenges related to disk IO in building a system like this, and how VMware FT addresses these challenges.
Issue #1 #
Simultaneous disk operations to the same location can lead to non-determinism, since these operations can execute in parallel and are non-blocking.
Solution #
Their implementation is able to detect such IO races and force racing disk operations to execute sequentially.
Issue #2 #
What happens with disk IO operations that are not completed on the primary due to a failure, and the backup takes over? The challenge here is that the backup cannot know whether or not the operation completed successfully.
Solution #
Those operations are simply reissued.
Issue #3 #
If a network packet or requested disk block arrives and needs to be copied into the main memory of the primary VM while an application running in the VM is also reading from the same memory, that application may or may not see the new data coming in. This non-determinism is a race condition.
Solution #
They avoid this race by using bounce buffers to temporarily hold any incoming packet or disk block in the primary VM. When the data is copied to the buffer, the primary is interrupted and the bounce buffer is copied into the primary's memory, after which it can resume its execution. This interrupt is logged as an entry in the logging channel, ensuring that both the primary and backup will execute the operations at the same time.
Design Alternatives #
This section compares some alternative design choices that were explored before the implementation of VMware FT and the tradeoffs they settled for.
- Shared vs Non-shared Disk: The implementation of VMware FT uses a shared storage that is accessible to both the primary and backup VMs. In an alternative design, the VMs could have separate virtual disks which they can write to separately. This design could be used in situations where shared storage is not accessible to both the primary and secondary VM or shared storage is too expensive. A disadvantage of the non-shared design in this system is that extra work needs to be done to keep not just the running states in sync, but also their disk states.
-
Executing Disk Reads on the Backup VM: In the current implementation, the results of disk reads from the primary VM are sent to the backup via the logging channel. In an alternative design, the backup VM could just perform its disk reads directly. This approach can help to reduce the logging channel traffic when a lot of disk reads are involved in a workload. However, two main challenges with this approach are:
- It may slow down the execution of the backup VM. Remember that we need the backup VM to execute quickly to speed up the failover process.
- What if the read succeeds on the primary but fails on the backup(and vice versa)?
Performance evaluation by VMware showed that executing disk reads on the backup slowed down throughput by 1-4%, but also reduced the logging bandwidth.
Conclusion #
This was an interesting lecture for me because my knowledge of replication was limited to data replication (application-level state), and so getting exposed to a different approach has been a good experience.
One limitation of this system is that it only supports uniprocessor executions, as the non-determinism involved in multi-core parallelism will make it even more challenging to implement. VMware has since extended the system described in the paper with an implementation that does support mutli-core parallelism. I do not know the details of that system yet and can't say much about what has changed.
Open Question I Have #
In the section on detecting and handling failures, it was mentioned that an atomic test-and-set operation is used to prevent split-brain scenarios. What is unclear to me is how those operations work.
According to the FAQ on the course website for this lecture, the pseudocode of such an operation looks like:
test-and-set() {
acquire_lock()
if flag == true:
release_lock()
return false
else:
flag = true
release_lock()
return trueWhat is unclear to me is when the flag is set to false; i.e. if the operation succeeds for a VM, does that VM set the flag to false when it is about to fail? I'm assuming it does, but would like some confirmation on this.
Update #
I sent an email about the above question to the course staff and got this response from Prof. Morris on how the ATS operation works:
The flag is ordinarily false, when both primary and backup are alive.
If the primary and backup stop being able to talk to each other, the one
that is alive will use test-and-set to set the flag and acquire the
right to "go live". If both are alive but can't talk to each other, both
may call test-and-set() but only one will get a "true" return value, so
only one will go live -- thus avoiding split brain.The paper doesn't say when the flag is cleared to false. Perhaps a
human administrator does it after restarting the failed server and
ensuring that it's up to date. Perhaps the server that "went live"
clears the flag after it sees that the other server is alive again
and is up to date.
Further Reading #
- Lecture 4: Primary/Backup Replication - MIT 6.824 Lecture Notes.
- Failure Modes In Distributed Systems by Alvaro Videla
Last updated on 12-05-20.