MIT 6.824: Lecture 1 - MapReduce
· 4 min readBackground #
I started a study group with some of my friends where we'll be going through this course. Over the next couple of weeks, I intend to upload my notes from studying each week's material.
MapReduce #
This week's material focused on the MapReduce paradigm for data processing. The material included the seminal MapReduce paper by Jeff Dean and Sanjay Ghemawat, and an accompanying video lecture. Below are my notes from the materials and group discussion.
MapReduce is a system for parallelizing the computation of a large volume of data across multiple machines in a cluster. It achieves this by exposing a simple API for expressing these computations using two operations: Map and Reduce.
The Map task takes an input file and outputs a set of intermediate (key, value) pairs. The intermediate values with the same key are then grouped together and processed in the Reduce task for each distinct key.
Some examples of programs that can be expressed as MapReduce computations are:
- Word Count in Documents: Here, the map function can emit a (key, value) pair for each occurrence of a word like (word, count). The reduce function can then add all the counts for the same word and emit a (word, total count) pair.
- Distributed Grep: Grep is a regular expression search for a given pattern in a text document. To search across a large volume of documents, we could define a map function which emits a line if it matches the supplied pattern like (pattern, line). The reduce function then outputs all the lines from the intermediate values for the given key.
- Distributed Sort: We can have a map function which extracts the key from each record and emits a (key, record) pair. Depending on the partitioning and ordering scheme, we can then have a reduce function that emits all the pairs unchanged. We'll go into more detail on the ordering scheme later on.
Implementation Details #
The MapReduce interface can be implemented in many ways, so this section just details the implementation specific to Google at the time of writing this paper.
The Map function invocations are distributed across multiple machines by automatically partitioning the input data into a set of M splits. The Reduce invocations are split into R pieces based on a partitioning function defined on the intermediate key.
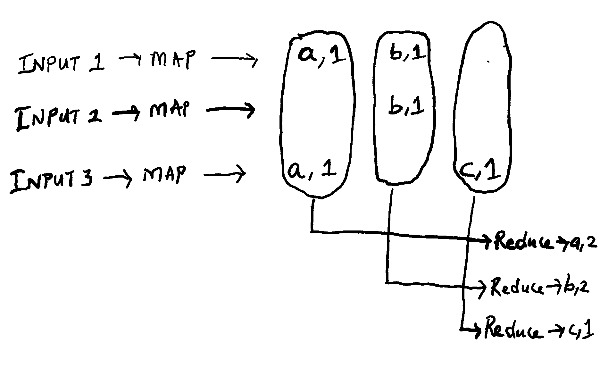
A sample MapReduce Job
The flow of execution when the MapReduce function is called by a user is as follows:
- The MapReduce library splits the input into M files and starts up multiple instances of the program on many machines in the cluster.
- One of the instances is the Master and the others are Workers. The master assigns map tasks to the available workers.
- There are M map tasks and R reduce tasks to be assigned to workers.
- When a worker is assigned a map task, it reads the input from its corresponding split, performs the specified operations, and then emits intermediate (key, value) pairs which are buffered in memory.
- These buffered pairs are periodically written to local disk, partitioned into R regions according to the partitioning scheme. The locations of these buffered pairs on local disk are passed to the master, which then forwards these locations to the reduce workers.
- A reduce worker uses remote procedure calls to read the buffered data from local disk based on the location it was forwarded by master. When all intermediate data has been read, it sorts the values according to the key and groups all occurrences for the same key together.
- For each distinct intermediate key, the reduce worker passes its grouped values to the reduce function defined. The output of this reduce function is appended to a final output file for the partition.
- The master wakes up the user program and releases control when all the map and reduce tasks have been completed.
The output of a MapReduce job is a set of R files (one per reduce task).
Dealing with Faults #
- Worker Failure: The master pings all its workers periodically. If no response is received from a worker after a set period of time, the worker is marked as failed. The tasks assigned to the failed worker are then reassigned to other workers.
- Master Failure: As master failures were rare, their implementation simply aborted the whole execution if master failed, for the execution to be retried from the start. An alternative implementation could have made the master periodically checkpoint its state, so that a retry could pick up from where the execution left off.
Dealing with Network Resource Scarcity #
Their implementation at the time of writing the paper used locality as a means of conserving network bandwidth. This means that the input files were kept close to where they will be processed to avoid the network trip of transferring these large files. The Master's scheduling algorithm took the file location into account when determining what workers should execute what input files.
Note, the lecture video for the week explained that as Google's networking infrastructure was expanded and upgraded in later years, they relied less on this locality optimization.
Dealing with Stragglers #
Stragglers are machines that take longer time than usual to complete one of the last few map or reduce tasks. They addressed this by having the master schedule backup tasks when the computation is almost completed. A task is then marked as completed when either the primary or backup execution completes.
Some Other Interesting Features #
- Combiner Function: A user can specify a combiner function, which groups all the values for a key on a machine that performs a map task. The combiner function typically has the same code as the reduce function. The advantage of enabling this is that it can reduce the volume of the data being sent over the network to a reduce worker. I wonder why this isn't enabled by default?
- Skipping Bad Records: Instead of the entire execution failing because of few bad records, there's a mechanism in place for bad records to be skipped. This is acceptable in some instances e.g. when doing statistical analysis on a large dataset.
- Ordering Guarantees: The guarantee is that within a given reduce partition, the intermediate key value pairs are processed in increasing order of the keys. I was curious about where/how the sorting happens and it looks like in Hadoop MapReduce, data from the mappers are first sorted according to key in the mapper worker using Quicksort. This sorted data is then shuffled to the reduce workers. The reduce worker merges the sorted data from different mappers into one sorted set, similar to the merge routine in Mergesort.
Conclusion #
Though no longer in use at Google for a number of reasons, MapReduce fundamentally changed the way large-scale data processing architectures are built. It abstracted the complexity of dealing with parallelism, fault-tolerance and load balancing by exposing a simple API that allowed programmers without experience with these systems to distribute the processing of large datasets across a cluster of computers.